

L’ajout systématique de tous les index diagnostiqué par SQL Server via les DMV sys.dm_db_missing_index_details (et autres…), n’est pas une bonne idée. En effet on trouve souvent dans ces diagnostics, des index redondants ou inclus. Il faut donc étudier la pose de chaque index nouveau en fonction de toutes les demandes similaires, mais aussi en fonction des index similaires déjà en place.
Le batch fourni ci dessous propose une aide pour établir un tel diagnostic, par trois moyens :
- le nombre de colonne incluse de l’index diagnostiqué (colonne NB_INC) ainsi que le nombre de colonnes de la table (NB_COL), est ajouté au diagnostic, permettant d’éviter de créer des index ayant une clause INCLUDE trop lourde;
- les demandes sont triées par table puis clef d’index, permettant de visuellement se rendre compte si des index futurs pourraient être inclus dans d’autres index futurs;
- les index similaires déjà présents sont rendu visible via les colonnes KEY_INDEX_SIMILAR, INCLUDED_COLS_SIMILAR, et aussi INDEX_NAME_SIMILAR, INDEX_ID_SIMILAR.
La colonne N fournit un indice différent pour chaque demande d’index nouveau. Le résultat peut faire apparaître plusieurs similarités.
La colonne SQL_CREATE_INDEX fournit une commande SQL DDL pour créer l’index manquant. Le nom de l’index incluant en suffixe la date de création sous la forme AAAAMMJJ.
Les valeurs des paramètres @FILL_FACTOR (facteur de remplissage des pages d’index) et @FILE_GROUP (espace de stockage pour les index) peuvent être modifiées au gré des besoins et des spécifications.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
DECLARE @FILL_FACTOR TINYINT = 90, @FILE_GROUP sysname = 'PRIMARY'; -- verify if FILL FACTOR has a correct value IF @FILL_FACTOR NOT BETWEEN 1 AND 100 BEGIN RAISERROR ('FILL FACTOR parameter must be valued between 1 and 100. Given value is %d', 16, 1, @FILL_FACTOR); RETURN; END; -- verifiy if FILE GOUP name exists IF NOT EXISTS(SELECT * FROM sys.filegroups WHERE name = @FILE_GROUP) BEGIN RAISERROR ('FILE GROUP %s does not exists in this database.', 16, 1, @FILE_GROUP); RETURN; END; -- verify that the scanning depth of the indexing diagnosis is sufficient DECLARE @SQL_START DATETIME = (SELECT sqlserver_start_time FROM sys.dm_os_sys_info); DECLARE @SQL_START_STR CHAR(21) = CONVERT(CHAR(19), @SQL_START, 121); IF @SQL_START > DATEADD(day, -31, GETDATE()) BEGIN RAISERROR ('The server restarted on %s which is insufficient for a good indexing diagnosis. Try again in a few days', 16, 1, @SQL_START_STR); RETURN; END; WITH TXC AS (-- candidate indexes SELECT ROW_NUMBER() OVER(ORDER BY statement, equality_columns, inequality_columns) AS N, object_id, statement, equality_columns, inequality_columns, included_columns, COALESCE(equality_columns + N', ' + inequality_columns, equality_columns, inequality_columns) AS KEY_COLS, 1 + LEN(included_columns) - LEN(REPLACE(included_columns, N',', N'')) AS NB_INC, (SELECT COUNT(*) FROM sys.columns AS c WHERE is_computed = 0 AND is_filestream = 0 AND c.object_id = mid.object_id) as NB_COL FROM sys.dm_db_missing_index_details AS mid WHERE database_id = DB_ID() ), AKX AS (-- keys of already indexes SELECT STUFF((SELECT N', ' + N'[' + name + N']' FROM sys.index_columns AS ic JOIN sys.columns AS c ON ic.object_id = c.object_id AND ic.column_id = c.column_id WHERE ic.index_id BETWEEN 1 AND 999 AND ic.is_included_column = 0 AND ic.object_id = T.object_id AND ic.index_id = i.index_id ORDER BY ic.key_ordinal FOR XML PATH (N'')), 1, 2, N'') AS K, i.object_id, i.name AS INDEX_NAME, i.index_id FROM (SELECT DISTINCT object_id FROM TXC) AS T JOIN sys.indexes AS i ON T.object_id = i.object_id ), XSK AS ( -- finding existing similar indexes SELECT N, INDEX_NAME, K, index_id, LEN(KEY_COLS) - LEN(REPLACE(KEY_COLS, K, '')) AS SIMILARITY1, LEN(K) - LEN(REPLACE(K, KEY_COLS, '')) AS SIMILARITY2, RANK() OVER(PARTITION BY N ORDER BY LEN(KEY_COLS) - LEN(REPLACE(KEY_COLS, K, '')) DESC) AS R1, RANK() OVER(PARTITION BY N ORDER BY LEN(K) - LEN(REPLACE(K, KEY_COLS, '')) DESC) AS R2 FROM TXC LEFT OUTER JOIN AKX ON TXC.object_id = AKX.object_id AND REPLACE(REPLACE(KEY_COLS, N'[', N''), N']', N'') LIKE REPLACE(REPLACE(K, N'[', N''), N']', N'') + N'%' OR REPLACE(REPLACE(K, N'[', N''), N']', N'') LIKE REPLACE(REPLACE(KEY_COLS, N'[', N''), N']', N'') + N'%' ) -- ginving the diagnosis SELECT TXC.object_id, statement, NB_INC, NB_COL, equality_columns, inequality_columns, included_columns, TXC.N, KEY_COLS AS CANDIDATE_KEY_COLUMNS, K AS KEY_INDEX_SIMILAR, STUFF((SELECT N', ' + N'[' + name + N']' FROM sys.index_columns AS ic JOIN sys.columns AS c ON ic.object_id = c.object_id AND ic.column_id = c.column_id WHERE ic.index_id = XSK.index_id AND ic.is_included_column = 1 AND ic.object_id = TXC.object_id ORDER BY ic.index_column_id FOR XML PATH (N'')), 1, 2, N'') AS INCLUDED_COLS_SIMILAR, INDEX_NAME AS INDEX_NAME_SIMILAR, index_id AS INDEX_ID_SIMILAR, N'CREATE INDEX X_' + REPLACE(CAST(NEWID() AS NVARCHAR(36)), N'-', N'_') + N'_' + CONVERT(CHAR(8), GETDATE(), 112) + N' ON ' + statement + N' (' + KEY_COLS + ') ' + CASE WHEN included_columns IS NULL THEN N'' ELSE N' INCLUDE(' + included_columns + ') ' END + N' WITH(FILLFACTOR = 90);' AS SQL_CREATE_INDEX FROM TXC LEFT OUTER JOIN XSK ON TXC.N = XSK.N AND (R1 = 1 OR R2 = 1) ORDER BY statement, KEY_COLS; |
Les figures suivantes nous montrent une partie des résultats qui permettent d’aider au diagnostic de pose de ces nouveaux index :
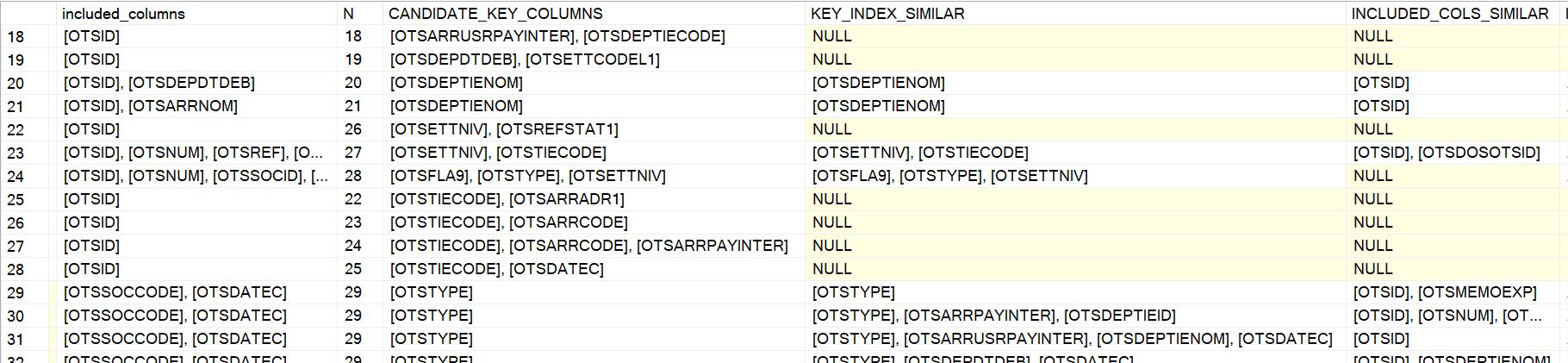
Il suffit d’analyser les colonnes CANDIDATE_KEY_COLUMNS et KEY_INDEX_SIMILAR (ainsi qu’éventuellement les colonnes incluses de part et d’autre) pour décider si l’on ajoute ou pas le nouvel index, ou bien si l’on modifie l’actuel index pour correspondre au besoin du nouveau.

Frédéric Brouard - SQLpro - ARCHITECTE DE DONNÉES - expert SGBDR et langage SQL
* Le site sur les SGBD relationnels et le SQL : https://sqlpro.developpez.com *
* le blog SQL, SQL Server, SGBDR... sur : https://blog.developpez.com/sqlpro/ *
* Expert Microsoft SQL Server, MVP (Most valuable Professional) depuis 14 ans *
* Entreprise SQL SPOT : modélisation, conseil, audit, optimisation, formation *
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *