
In a paper by Pankil Shah, EnterpriseDB which sells a paid version of PostGreSQL, tries to compare Microsoft SQL Server to PostGreSQL…
https://www.enterprisedb.com/blog/microsoft-sql-server-mssql-vs-postgresql-comparison-details-what-differences
Several false informations are given in this paper…
That’s why I decided to publish a correction to these data
Published 2021-04-03
Who am I?
At the moment I am 60 years old, and have roam in the database field since the very beginning. In my country (France) I am considered as an expert in RDBMS and for the SQL language. I have worked, since I am on the businees, with RDBMS Ingres (CA), DB2 (LUW), InterBase (Borland), Gupta SQL, Informix, Oracle, Sybase SQL Server, Sybase ASA (Watcom), RDB (Digital), MS SQL Server, PostGreSQL and MySQL…
After having worked for many IT companies or IT editors, I decide to found my own one in 2007 called SQL Spot in the French Riviera. By the way, I travel in France, Europe and some more over, to give my advices, assess and audits for small or big enterprises that’s need to be helped to decide, perfect and take full advantage of their RDBMS… At the same time, I gave courses in engineering schools as well as at the university
I am still active and as a man of experience, I know how to take sufficient distance to assess the risks and benefits of a particular system.
Some people think that I am acting against PostGreSQL … But as the saying goes « who likes well, catches well« . PostGreSQL must have its place in the sun, but its rightful place. Considering it as equal to an Oracle, an IBM DB2 or a SQL Server can prove to be catastrophic in certain cases, and in particular when the technical and functional preliminary studies have not been seriously established.
Some PostGreSQL fundamentalists have succeeded in introducing their favorite DBMS without any prior study or without any proof of concept, benchmarks or simple tests and this has often resulted in catastrophic adventures with a costly backtracking (case of Agic Arco retirement insurance in France for example), an abandonment of the solution after years of hardship (case of CAF in France for example which recently returned to the bosom of Oracle, or Altavia in which a newly CTO attempted to migrate from SQL Server to PostGreSQL without success…), or even expensive solutions in terms of operation, such as this is the case for the French website « Le Bon Coin » which uses more than a 70 PostGreSQL server and therefore near a hundred databases where all the others use only one server and one single database. Le Bon Coin having wisely opted for SQL Server for the BI part of its analytical service (with only one single server) against any solution based on PostGreSQL …
But it is clear that in some companies, a few postGreSQL ayatollahs come to impose an inadequate solution, even if it costs more than what it is supposed to bring, but on purpose, in order to keep a « private reserve » and become the king of data, to the detriment of users and the quality of service that we are entitled to expect from good corporate IT!
It is therefore in order not to have disappointments and specially to decide in full knowledge of the facts, that I invite you to read this corrigendum, which details the differences between PostGreSQL and Microsoft SQL Server in order to guide your choice.
Finally, I want to say that I have no professional connections with Microsoft and I do not have any MS stock market action and I have never sold any MS product, so I do not profit from Microsoft in any kind. I am a simple professional user of Microsoft products, database expert and specialized in SQL Server … Yes, I was a MS MVP (Most Valuable Professional) for many years, recently ended, and in this case I have been invited at Redmond (but I have paid my own ticket plane), to be informed, first of all, about what’s new in Microsoft SQL Server, exactly as the PG community does, with the PG days, in which I have participated by the past.
What is the difference between PostgreSQL and SQL Server licensing? Comparison of PostgreSQL vs. MSSQL Server licensing model
The author gives the licensing price for only 2 versions of SQL Server (Standard and Enterprise).
But there is almost 4 different versions on premise and one in the cloud.
One version, SQL Server Express is free but limited at 10 Gb of relational data per DB, with a maximum of 32760 databases. Non relational data are unlimited (FILESTREAM, Filetable…).
Another version called Web that can be used only in SLA mode, is about 50 $ per month. The limits are on hardware resources (max 4 socket 16 cores / 32 with hyperthreading and 64 Gb RAM for classical relational table + 16 Gb of « in memory » table that PostGreSQL doesn’t have + 16 Gb of vertical indexing (columnstore) that PG doesn’t have).
EnterpriseDB, sales a paid version of PostGreSQL that corrects some disadvantages of the free version, like the lack of query hint…
Another important difference (omitted) is that SQL Server come with a full stack of operational services like:
- another dbengine for BI : cube and datamining (call SSAS : SQL Server Analysis Services)
- an ETL named SSIS (SQL Server Integration Services – World record: 1 Tb in 30 minutes)
- a solution for reporting call SSRS (SQL Server Reporting Services)
- a solution for self BI call Power BI (only available in the Enterprise edition)
With no needs to paid extra for anything….
No one of theses solutions (ETL, reporting, BI, data mining….) are available with PostGreSQL. But some solutions exist has free with some limitations that are not suitable for enterprise purpose (as an example, the free ETL Talend has some restricted functionality which requires a paid version to use it when you have a great amount of data… parallelism). Of course all those disparate solution are less well integrated becauses they came from different software vendors and causes some troubles that are unknown in the Microsoft world (which has always made it its strength)…
If you want Enterprise professional solutions, you have to pay EnterpriseDB or Fujitsu…
Which of PostgreSQL or SQL Server is easier to use? Compare the ease of use of PostgreSQL vs. MSSQL
To remain complete, the origin of SQL Server is from Sybase SQL Server (born 1983, from INGRES !), and derived in to branches, one for Sybase renamed ASE (Adaptive Server Enterprise) and the Other MS SQL Server. It is true that the first Microsoft version of SQL Server was done in 1989.
The author seems to say that SQL Server has no object relational functionality… This is false. Objects storage can be done by coding in a .net language (CLR) and integrated as datatypes of any database, and these objects can have methods to operate them. All the SQL CLR objects created reside into the database not outside… And all theses objets can be indexed as long as they are « byte ordered ».
In addition, SQL Server has some noSQL features that PostGreSQL does not have : graph tables, big table (up to 30000 columns), « in memory » tables (for the key-value paired tables but not only…), and document storage via FILESTREAM/FileTable with Fulltext and semantic searches.
No one of these features are available in PostGreSQL.
SQL Server has an XML datatype in which XML data can be fully indexed. Indexing XML does not exists in PostGreSQL !
What are the syntax differences between PostgreSQL and SQL Server? Compare PostgreSQL vs. MSSQL Server Syntax
The author shows some old Sybase inherited syntax, with some bad faith, to indicate that syntaxes of SQL Server is abnormal and not portable which il clearly false!
In truth SQL Server can do a
SELECT col1, col2
without brackets, and aliases can be create with the keyword AS (or without). The old syntaxes presented by the author resides for some compatibility reasons, but in my life (40 years of RDBMS uses), I never see some customer using it since more than 20 years !
Also the below syntax given by the author:
SELECT AVG(col1)=avg1
Does not exists in SQL Server and throw an exception:
|
1 2 |
<em><span style="color: #ff0000;">Msg 102, Niveau 15, État 1, Ligne 2</span></em> <em><span style="color: #ff0000;">Incorrect syntax near '='.</span></em> |
Which proves that the author does not even check his own writings… The correct old fashioned and unused syntax is
SELECT avg1=AVG(col1) ...
Finally, when working with dates, you can use the standard ISO SQL function CURRENT_TIMESTAMP (without parenthesis as the standard require).
What are the data types differences between PostgreSQL and SQL Server? Compare data types in PostgreSQL vs. MSSQL
The author committed some errors, by giving some correspondent datatype that are no more used…
In particular, the TEXT datatype is obsolete since 2005 and must be replace by VARCHAR(max) for ASCII style encoding or NVARCHAR(max) for UNICODE style encoding.
The DOUBLE PRECISION that the author mention, does not exists in SQL Server with this name, bust you need to use a REAL which is the strict equivalent.
In a matter of UUID or GUID, PostGreSQL does not have any correspondent datatype and store it in a CHAR(16) which as some major disadvantages: using more space than required and does not complies all the features of such a datatype needs like sorting or the inequality comparison…
Worse, as we will discuss later, PostGreSQL implicit data casting results some anomalies that can be dangerous…
Another significative difference about datatype is that the bit type of SQL Server (that acts as boolean) is really a bit, not a byte and multiple bits use the same byte up to eight bits. This is to say that using boolean types in SQL Server is eight-time thinner rather than PostGreSQL…. and some features performs radically faster when using a bit datatype in SQL Server rather than a boolean in PostGreSQL
What are the case sensitivity differences between PostgreSQL and SQL Server? Compare collations in PostgreSQL vs. MSSQL
Great mistakes and misunderstood has been deliver in this paragraph.
First of all, MS SQL Server is not case sensitive or case insensitive. The default sensitivity for case, accent, kanatype, wideness and some more features for string collations must be decided when installing an instance of SQL Server.
In SQL Server, the collation settings can be set as the instance level (called « cluster » in PG), at the database level when creating, at the column level when creating or altering a table or a view, and finally the COLLATE operator can be used in any string expression of any query, that PostGreSQL do not support.
SQL Server’s Collations supports 68 different languages and can be CS or CI (case sensitivity), AS or AI (accent and diacritical sensitivity), width sensitive or not (WS), kanatype sensitive or not (KS) for Japanese and also sensitive to ideographic variation or not (VSS), or more simply binary (BIN or BIN2) and finally SC for some supplemental characters like smiley or, at last, UTF-8. PostgreSQL collations are limited to CI/CS and AI/AS.
PostGreSQL don’t have so much functionalities relative to collations and COLLATE operator.
There are over 5,500 collations in SQL Server compare to the very poor number of collation of PostgreSQL. But PostGreSQL recently add ICU collations but theses collations are severely bugged. As an example, SQL operator « LIKE » with an ICU PG collation won’t execute the query and give an astouding « non deterministic » collation error!
This is a real problem when you want to use PostGreSQL with Latin languages that have accents (Europe, South America, North Africa…. A lot of people!)
The problem is also that classical collation based on linux system can corrupt your indexes!
In short, with PostGreSQL the choice of collation is between plague and cholera …
What are the index types differences between PostgreSQL and SQL Server? Compare index types in PostgreSQL vs. MSSQL
First, there is no CLUSTERED index in PostGreSQL, like SQL Server’s one or the IOT of Oracle Database. Clustered indexes have some great advantages in terms of data storage (less bytes, because clustered index leaf pages are stored into the table and not outside – eg no duplicate data) and also in terms of pure performances: especially in joins, because every non clustered indexes have the value of the clustered key (often the PK) and no more requires a table access to do the « seek and join » part of a query…
The author forgets to say that PostGreSQL has recently add the INCLUDE clause to there traditional BTree indexes like that has been done in Microsoft SQL Server since many years (2005) in order to ensure the coverage of the query by the index.
Yes, PG has the advantage to give hash indexing…. PostGreSQL had also recommended to not uses them! Hash index exists also in SQL Server but are dedicated to « in memory » tables.
GiST, GIN and BRIN index types have never been implemented other than in PostGreSQL …. Ask yourself the reason …!
SQL Server also has vertical indexes (columnstore index, since 2012 version), that the author has omitted, and which are intended for indexing very large tables. Such indexes are essential as soon as you must reach hundreds of millions of lines because data stored in such indexes are always compressed and this type of index can be seek in « batch » mode: blocks of data rows accessed in parallel, rather than in the traditional row-by-row mode which subsist in classic indexes such as PostGreSQL uses them … Vertical indexes does exists in the Citus version of PostGreSQL (Citus has been acquired by Microsoft) but they are not working as fast as SQL Server’s one and are dedicated to OLAP not for OLTP databases. Another solution is to change your version of PostGreSQL to a paid and expensive version such as the one sold by Fujitsu …. Also, SQL Server’s columnstore index can support 1024 columns in the index key (traditional BTree index are limited to 32 columns in both SQL Server and PostGreSQL).
Vertcial indexing does not exist in PostGreSQL.
For « in memory » table, SQL Server offers hash indexes and have add a more sophisticated range index called BWTree, that PostGreSQL does not have because PostGreSQL does not support « in memory » tables.
For XML, SQL Server give 4 types of indexes (PRIMARY, FOR PATH, FOR VALUE, FOR PROPERTY) that covers full XML documents, and not only a single partial element that your have to redounds in order to dispose an atomic index value, like this is the case in PostGreSQL! In the facts, PostgreSQL has no XML index at all…
What are the replication differences between PostgreSQL and SQL Server? Compare replication in PostgreSQL vs. MSSQL
The author is completely wrong about this subject, and confuses about what is in the field of high availability (which it did not mention in the paper for SQL Server) and what is in the field of scalability (replication of some data, filtered by rows and columns, to other databases and instances of SQL Server).
For the data replication (not used for High Availability) SQL Server has 8 modes to communicate:
- transactional replication (for read/write parts of tables from a database to many other databases, with no reverse)
- peer to peer replication, based on transactions (for read/write parts of tables from some databases to some other databases, with no reverse for the data replicated)
- merge replication (for read/write parts of tables from many databases to many other databases, with reverse)
- snapshot replication for read/write tables from a database to many other databases, with no reverse)
- Oracle replication (special case)
- Service Broker (to communicate data from different databases with different table schemas, with reverse)
- The use of triggers and linked servers (that I do not recommend…)
- The MS ActiveSync (that I do not recommend too…)
Data replication is a feature in which you choose the tables, the rows and the columns in the tables that you want to be replicated, from one database to another one on another instance. So, you can replicate small part of some tables, and SQL Server permits to replicate the execution of stored procedures instead of row values…
Many big websites use transactional replication to increase the data attack surface in order to reach tens of thousands of users simultaneously. This must be combined with DPV (Distributed Partitioned View – another feature that PostGreSQL don’t have). In France, CDiscount, Ventes Privées (aka veepee), FNAC, and many others who are part of the top 10 merchant websites use this functionality on MS SQL server clusters running in parallel …
For the High Availability (not used to replicate some data from some databases to some other), SQL Server has 3 modes:
- Mirroring: per database, a full synchronized (or not) copy of the database to another server (LAN or WAN) with ability to fail over automatically (copies of databases are called « replicas » and cannot be readable not writable). This feature has been deprecated to the profit of AwaysOn Technology, but is still suitable for small use cases.
- Log Shipping: per database, an asynchronous copy of the database to another server (LAN or WAN) without any internal ability to fail over automatically. I must say that PostGreSQL can do that, but in MS SQL Server some assistants help the DBA to do that in less than a minute, with a full coverage of automatic telemetry diagnostics!
- AlwaysOn: per groups of databases (called « Availability Group » or AG) a full synchronized (or not) copy of all the databases in the group to many other servers (LAN or WAN) with the ability to fail over automatically. Copies of databases are called « replicas » and can be set in a readable mode in order to ensure SELECT queries or backup features.
I must say that I have never seen any PostGreSQL high availability system that have automatic failover capabilities, totally transparent for the applications that Microsoft SQL Server have! And some PostGreSQL SQL queries will broke the system (ALTER TABLE, DROP TABLE, TRUNCATE, DROP INDEX, CREATE TABLESPACE… for example).
More, somme commands that Microsoft SQL Server replicates, like creating a new tablespace (called filegroups in SQL Server) with some files to store new tables or indexes, is strictly impossible in PostGreSQL streaming replication.
This generates a lot of replication conflicts, well explained in this paper:
Dealing with streaming replication conflicts in PostgreSQL
MS SQL Server AlwaysOn technology inducing « availability groups » combine failover cluster and streaming transactional based on the binary resulting of the transaction (not on the logical replication of transactions like PostGreSQL do) in synchronous or asynchronous mode in order to:
- assume Business Continuity automatically with some local nodes in synchronous mode and automatic failover;
- assume Business Continuity manually with some local nodes in synchronous or asynchronous mode and manual failover;
- assume Disaster Recovery with some local or distant nodes in asynchronous and manual failover;
- assume extensibility of data access with some local or distant nodes in synchronous or asynchronous mode with databases in a readable setting.
This technology can be set in a divergent way in the Linux version of SQL Server and some nodes can reside in Azure cloud.
AlwaysOn can have actually 8 nodes with a maximum of 3 in synchronous and automatic failover, the others must be in asynchronous and, of course, manual failover.
The automatic synchronous failover of SQL Server via AlwaysOn guarantee that there is no loss of data of any kind , even if you add some new storage to a database (called FILEGROUPs in SQL Server)….. PostGreSQL streaming replication, even in synchronous mode, is not able to guarantee no loss, and some SQL statements cannot be replicated on the slave nodes!
As an example, we have done the AlwaysOn high availability for the worlwide transportation company Geodis with more than 130 databases over 5 replicas (instances of SQL Server) with about 14 To of data (2014).
I remember by the past that, in a pdf document, the PG dba of « Le Bon Coin » was proud to have solved a major failure of the high availability process of PostGreSQL in a few days… but they forgot to mention that the main databases was running without any safety « net » during those same days…
PostGreSQL Streaming Replication also requires some modifications of the database to be able to execute such as the presence of a primary key for all tables … While no prior modification is necessary to implement the Microsoft SQL Server AlwaysOn solution.
Other major differences between PostGreSQL streaming replication and SQL Server AlwaysOn are:
- Automatic seeding is used in SQL Server AlwaysOn solution to automatically send the source database to the secondary instances in order to implement the concerned replicas. No automation of this type of process exists in PostGreSQL streaming replication and this results in a waste of time, especially when large databases must be involved.
- SQL Server AlwaysOn technology can use compression for many operations like seeding or data replication with distant commit. There in no compression of any kind in PostGreSQL for the streaming replication… This results in a heavy traffic on the network when the replication process operates with many databases.
- Encryption is specifically by default for AlwaysOn SQL Server high availability, but PostGreSQL streaming replication cannot cypher the data transmitted… Of course, you can use SSL or VPN… But in some circumstances, an internal and specific encryption is preferable, especially when data are very sensitive like health care or financial…
- PostGreSQL can only replicate all the databases of a cluster. It is impossible in PostGreSQL to replicate only one database in the case of the source cluster have many databases, nor a subset of databases... SQL Server can, not only replicate one database in an instance that hosts many databases, but also a group of database called « Availability Group » that needs to be simultaneously failed over… And finally, SQL Server AlwaysOn offers the possibility to dispatch the different groups of databases to be simultaneously failed over on different targets.
- PostGreSQL can failover only when the PostGreSQL engine crash. There is no possibility for PostGreSQL to failover automatically when a crash occur at the physical level nor the VM or the database… By contrast, MS SQL Server with the Windows Failover Cluster (WFCS) detects all troubles at any level : physical machine, VM, SQL instance or database…
Why PostGreSQL replication is so complicated and limited ?
The technology used in PostGreSQL streaming replication is the equivalent of the transactional replication of SQL Server, that is not used for high availability due to many limitations. It is based on logical not the physical level. Replication at the logical level have some mousetrap. To make it simple, the logical replication of a simple UPDATE that catch the current timestamp will not generate the same value on all the replicas, due to the asynchronous propagation of the logical SQL command… The same trouble appears when generating a UUID to keep as a a key value, even in synchronous streaming replication.
Binary transactionnal replications that copies bytes, have always exact values and at the same time and did not lock at all, because this process does not replicate a transaction but the consequences of the transaction… This subtil point make all the difference!
This was one of the many reasons that Uber shift from PostGreSQL to MySQL… And this is combined with the bad behaviour of MVCC in the replication process…
To avoid those problems, Microsoft SQL Server opted for physical (binary) replication comming with the 2005 version (mirroring), that copies parts of the transaction logs stored as binary values of data, to be lately recorded in target table or index, pages. Thus, it’s guarantee that the values are strictly the same over all the database, whatever the time of the replication is, synchronous or asynchronous and whatever the computed values are, when nondeterministic calculus are runs…
What are the differences in clustering between PostgreSQL and SQL Server? Compare clustering in PostgreSQL vs. MSSQL
Here again the author says false things … SQL Server have no active/active clustering capabilities.
In the facts, there is a possibility to have several instances of SQL Server (the name « instance » refers to the term « cluster » in PG) on one machine and having some in active mode and some other in passive mode (in that case, the SQL Server service of some instances is turned off). With a shared disk that is accessible by all the instances of SQL Server, a crash of one computer is fail over manually or automatically by one another that access the disk share when restarting the SQL Server service instance… But this is an old fashion to do what we call high availability and the most actual way to do this is to use AlwaysOn technology as write in the above paragraph.
Excepting through the merge data replication, there is no way to have a full database that is writable by many instances of SQL server running on different machines. But with AlwaysOn it is possible to have one active database (read/write) and many other replicas readable.
What are the trigger differences between PostgreSQL and SQL Server? Compare the triggers in PostgreSQL vs. MSSQL
Both SQL Server and PostGreSQL supports PER STATEMENT triggers. This is new in PG (2018), but old in SQL Server since almost 1999… But the main difference is that SQL Server triggers can modify directly the data of the targeted table without some « contortion » of the code in order to avoid the mutating table error… PostGreSQL triggers are subject to uncontrolled recursion in this case. SQL Server controls the recursion in two manners: at the database level (for recursion) and at the server level (for re-entrance, e.g. for what I call « ping-pong » trigger).
|
1 2 3 4 5 6 7 8 9 |
CREATE TRIGGER E_IU_CUSTOMER ON T_CUSTOMER_CMR FOR INSERT, UPDATE AS IF NOT UPDATE(CMR_NAME) RETURN; UPDATE T_CUSTOMER_CMR SET CMR_NAME = UPPER(CMR_NAME) WHERE CMR_ID IN (SELECT CMR_ID FROM inserted); |
Here is and example of SQL Server trigger code that forces the uppercase of names in a customer table, each time a name is inserted or deleted.
Both PostGreSQL and SQL Server have DDL triggers, but the way it is implemented in SQL Server is more accurate (about 460 events or event groups on two different levels: server scope – 201 – and database scope – 262), fully usable and uses a simplest code. As an example, forbidding a CREATE TABLE that does not meet certain criteria, is easy in SQL Server and use 6 lines of code:
|
1 2 3 4 5 6 7 |
CREATE TRIGGER E_DDL_CREATE_TABLE ON DATABASE FOR CREATE_TABLE AS IF EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)[1]', 'sysname') NOT LIKE 'T?_%' ESCAPE '?' ROLLBACK; |
… but in PostgreSQL, you needs two objects and to code 20 lines with a more complex logic :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE FUNCTION e_ddl_create_table_func() RETURNS event_trigger LANGUAGE plpgsql AS $$ DECLARE obj record; BEGIN FOR obj IN SELECT * FROM pg_event_trigger_ddl_commands() WHERE command_tag in ('CREATE TABLE') LOOP IF NOT (parse_ident(obj.object_identity))[2] LIKE 't?_%' ESCAPE '?' THEN raise EXCEPTION 'The table name must begin with t_'; END IF; END LOOP; END; $$; CREATE EVENT TRIGGER trg_create_table ON ddl_command_end WHEN TAG IN ('CREATE TABLE') EXECUTE PROCEDURE e_ddl_create_table_func(); |
In SQL Server, when you have multiple triggers for the same object and the same event, you can control the order the triggers fires (sp_settriggerorder). In PostGreSQL the order the triggers fires is fixed by the name (in alphabetic order)! Not quite easy when multiple contributions must set their own triggers (remember, many tools use and abuses of triggers, because it is the only way to capture data changes in PostGreSQL). By contrast, most of the features of SQL Server that require tracking down a change in data uses the transaction log, which is much lighter than using a trigger…
What are the query differences between PostgreSQL and SQL Server? Compare the query in PostgreSQL vs. MSSQL
Here too the author omits elements of comparison…
SQL Server can also add to standard SQL, advanced types and user-defined types, extensions and custom modules, and additional options for triggers and other functionality, by coding those topics in a .net language (C#, Python, Ruby, Scheme, C++…).
And the support a JSON is include natively.
But… PostGreSQL has no MERGE statement (which is a part of ISO SQL Standard).
What are the full-text search differences between PostgreSQL and SQL Server? Compare full-text search in PostgreSQL vs. MSSQL
The author says that « SQL Server offers full-text search as an optional component » which is a lie…. FullText indexing is a full part integrated in SQL Server by Microsoft since the 2008 version of SQL Server!
PostGreSQL indexing is completely proprietary while SQL Server acts in the ISO standard SQL way with the CONTAINS statement.
But SQL Server have some more features that PostgreSQL does not have:
- indexing a great amount of different file format (all the MS office type of files plus .txt, xml, rtf, html, pdf…)
- indexing documents stored as files with the FILESTREAM/Filetable storage
- using semantic indexing
- indexing meta tags in electronics documents
- searching synonyms has no limitations like PG has
- easy searching of expand or contracted terms (acronym)
What are the regular expression differences between PostgreSQL and SQL Server? Compare regular expressions in PostgreSQL vs. MSSQL
It is true that MS SQL Server has no natively regex support, this was done on purpose for security reasons (essentially because of DOS attacks…), but:
- the LIKE operator has some REGEX functionalities ( […], ^…);
- the sensitivity (or not) for characters strings like case, accents (and all diacritics characters like ligatures) kanatype, width (2 = ² ?) can be set while using the LIKE operator combined with a collation, which is required in the standard ISO SQL;
- REGEX full functionality can be operated by adding a .net DLL written in C# by Microsoft as an UDF (User Defined Function)
But, and this is very worrying, the combination of a case-insensitive collation (ICU collation in PostGreSQL) and the LIKE operator, consistently causes a particularly astounding error (ERROR: nondeterministic collations are not supported for LIKE ...) which makes such search unusable!
I don’t know what is the concept of « nondeterministic » collation, because a collation is a simple surjective mathematic application between two sets, one containing the original chars and the second the transformed chars… But the result is in facts that PostGreSQL does not have fully feature to retrieve information when you need case or accent insensitive searches!
But the main reason for the lack of a built-in function, like the standard requires (SIMILAR), is that it facilitates denial of service attacks! Having a standard function known to everyone is a catastrophic entry point that makes attacking PostgreSQL servers easier by SQL injection! In SQL Server, via the CLR.net DLL that give the regex features, you can create a user defined function with a customized name… which is more difficult to find for a hacker. The PG documentation is also clear about that point….
Problem you cannot remove easily all the regex stuff of PG like SIMILAR, ~, ~*, !~, !~*, substring, regexp_replace, regexp_split_to_array. Trying to remove the regex part of the substring function, is just a nightmare… Of course, you can do it because you can get the source code…. But how many years will it take to do so?
What are the partitioning differences between PostgreSQL and SQL Server? Compare the partitioning in PostgreSQL vs. MSSQL
One major difference between PostGreSQL and Microsoft SQL Server in the topic of partitioning, is that, the partition mechanism is generic and complete… Resulting in saving, time, money and security!
When you are creating partitions in PostGreSQL you have to create one new table (inherited) for each partition of each table… If you have 30 tables and need to divide the data by month over 3 years, you need to create 1080 inherited PostGreSQL tables! What wasted time….
In SQL Server partitioning system, there is only two objects to create to manage all the partitions you want on all the targeted tables:
- a partition function (CREATE PARTITION FUNCTION);
- a partition schema (CREATE PARTITION SCHEME);
Finally you must do an alter table for each tables or indexes involved in the partitions to indicate that they have to store the rows in the partitioned system when they don’t have been stored in partition.
Adding a partition in SQL Server for all the tables of your partitioned data, results by launching two single commands (ALTER PARTITION SCHEME…, ALTER PARTITION FUNCTION…).
For instance, I have to create the Operational Data Store of E.Leclerc accounting (which is an equivalent of Walmart in France) and we decided to partition about 30 tables by store, and with about 300 stores, the result is near 9000 units of storage… This has been taken only 10 minutes to do!
As an example, consider the orders made on a website that we want to partition by date:
- For recent invoices, with a partition per quarter up to year n-1 compared to the current year.
- For old invoices (years n-2 and even older), a partitioning per year will be carried out.
This is summarized by the following figure:

Principle of partitioning in SQL Server
PostGreSQL solution’s based on Oracle way of partitioning has several gotchas, because the partition mechanism is based on designing intervals:
- You can « forget » some values of key partitioning.
- You can create partition overlapping
SQL Server solution systematically offers continuity of partitioning, so there are no possibilities to forget some key partitioning values or to have an overlap between two partitions….
By the way, let’s talk Ted Codd, the Relational DB creator, about partitioning…
Rule 11: Distribution independence: The end-user must not be able to see that the data is distributed over various locations. Users should always get the impression that the data is located at one site only.
What do you think of this rule in relation to the fact that, in PG, you need to design new tables to create partitioning? A table is a logical location of data!
Some more problems remains in PostGreSQL solution:
- PostGreSQL does not allow to partition an existing table. This is a severe limitation, because you cannot always knows, when designing the database, if this or that table must be partionned. Usually you have to wait for the growth of the database size!
- PostGreSQL cannot create global indexes on partitioned tables. Those indexes are widely used, because many queries does not have the partition criteria in the WHERE clause…
- PostGreSQL cannot create UNIQUE constraints on partitionned tables. Because the pseudo partitionned table is not a table but a collection of table it’is impossible, by definition, to have a « transversal » unique constraints that checks all the rows of all the child table… Read…
- PostGreSQL does not offers support for « splitting » or « merging » partitions using dedicated commands;
- PostGreSQL cannot make a partition non-writable (as an example for archive purpose);
- PostGreSQL cannot compress a partition (as an example for lukewarm data).
What are the table scalability differences between PostgreSQL and SQL Server? Compare the table scalability in PostgreSQL vs. MSSQL
The author forget to say that SQL Server has a system called Data Partitioned Views (DPV) that allow horizontal partitioning and give a way to run parallels instances of SQL Server to offer a wider attack surface for the data. As an example, fnac.com (our « French » amazon) uses a farm of servers running simultaneously.
But this topic must rely to the paragraph « What are the replication differences between PostgreSQL and SQL Server? Compare replication in PostgreSQL vs. MSSQL »
What are the compliance differences between PostgreSQL and SQL Server? Compare the compliance in PostgreSQL vs. MSSQL
The author seems to indicates that SQL Server has no compliance for HIPAA, GDPR, and PCI. in the facts SQL Server has a higher level of compliance for many of theses requirement.
As an instance, I would mention fourth features that PostGreSQL don’t have and which are very great for securing the databases:
- Transparent Data Encryption : cyphering the data in the files (tables, indexes and transaction log (even in tempdb which is used for temporary tables) and of courses all the backups done on the database
- End-to-end encryption: allows clients to encrypt sensitive data inside client applications and never reveal the encryption keys to the Database Engine
- Extensible Key Management: encryption keys for data and key encryption are created in transient key containers called HSM residing outside the machine in a secure electronic device called HSM (Hardware Security Module)
- Dynamic Data Masking: limits sensitive data exposure by masking it to non-privileged users.
There are many more features that I can talk about for this topic that make the difference, but those based on encryption features are the most sensitive ones…
What are the NoSQL capability differences between PostgreSQL and SQL Server? Compare the NoSQL capabilities in PostgreSQL vs. MSSQL
By omitting some crucial information, the author is lying about the ability to do NoSQL…
First SQL has JSON features exactly like PostGreSQL.
As I said, earlier :
- Second, Microsoft SQL Server have graph table that PostGreSQL don’t have
- Third, Microsoft SQL Server have « in memory » table that PostGreSQL don’t have
- Fourth, Microsoft SQL Server have « big table » up to 30000 columns and vertical indexing (columnstore index) that PostGreSQL cannot… Plus SQL Server Big Data clusters…
- Fifth, Microsoft SQL Server can create « key value » pair table (in memory) that PostGreSQL don’t have
So PostGreSQL has very few NoSQL features, only JSON… While SQL Server has the major NoSQL features !
What are the security differences between PostgreSQL and SQL server? Compare the security in PostgreSQL vs. MSSQL
There are some important differences between PostgreSQL and Microsoft SQL Server in the matter of security.
First PostgreSQL has never been designed in though by dissociating the security level of the operations on the « cluster » (such as creating a new database, controlling the connections, backuping…) and the commands at the database level.
As an example, a backup (that does not exists in PostGreSQL which does a dump…) can be controlled at the database level, but in PG, is outside the scope of the database, and also outside the security of the PG cluster! Conversely SQL Server use a security entity named « connection » for the instance operations, and another entity security named SQL user at the database level, in which a connection can be linked to only one SQL user in each database.
The complete list of SQL server’s privileges at all levels can be view on a poster in pdf format. As you can see, the sharpness of privileges in SQL Server has no comparison with the coarse privileges in PG.
I must say that PostGreSQL has some efforts to do in the matter of security:
- CVE-2019-10164 at level 9.0 shows that an attack by elevating privilege is possible
- CVE-2019-9193 at level 9.0 show that COPY TO/FROM program allows superusers to execute arbitrary code
- CVE-2018-16850 at level 7.5 is vulnerable to a to SQL injection in pg_upgrade and pg_dump
And SQL Server database engine is well known as the most secure database system… No CVE at level over 6.5 (critical) has been discover in the past 12 months…
What are the analytical function differences between PostgreSQL and SQL server? Compare the analytical functions in PostgreSQL vs. MSSQL
The author forgot to mention that: DENSE_RANK, NTILE, PERCENT_RANK, RANK and ROW_NUMBER that SQL Server also have!
What are the administration and GUI tools differences between PostgreSQL and SQL server? Compare the administration with GUI tools in PostgreSQL vs. MSSQL
The author forgot to mention that: DBeaver, Squirell, Toad… are also administrative tools available for SQL Server and monitoring health and performance tools includes Nagios, Solar Winds, Idera, Sentry, Quest, RedGate, Apex…
What are the performance differences between PostgreSQL and SQL server? Compare the performance of PostgreSQL vs. MSSQL
The author says that « because the SQL Server user agreement prohibits the publication of benchmark testing without Microsoft’s prior written approval, head-to-head comparisons with other database systems are rare ». In facts such clauses in contracts are « leonine » clause and are not applicable, because they are against the laws, especially in the fields of human rights and of the freedom of expression.
So, you can publish benchmarks (I have published some’s) but, you must be fair in your comparisons, and it is the case when you use an approved benchmark like the ones that are available in the TPC org.
What I see, is that Microsoft has published a dozen of results for those benchmarks, and the current benchmark for OLTP database performances is the TPC E. But I have never seen any results for PostGreSQL of any kind, maybe because of the fear to be ridiculous…
Think about one thing… SQL Server database engine runs queries automatically in parallel mode since the 7.0 version (1998) and in practice, almost all the operations (over 100 types actually) in a query execution plan can be parallelized…. In PostGreSQL only 4 types of operations can use a multithreading internally which seems to be limited at 4 threads…!
With the help of « in memory » optimized table and columnstore indexes (vertical index), we are light-years away in terms of performances between SQL Server and PostGreSQL…
Ask yourself why no PostGreSQL OLTP benchmarks results have been published in the TPC.org…
What are the concurrency differences between PostgreSQL and SQL Server? Compare concurrency in PostgreSQL vs. MSSQL.
The author confuses about MVCC in SQL Server. Let’s talk about real facts.
Concurrency of accessing data is done by the standard ISO SQL isolation level that require 4 levels:
- READ UNCOMMITTED (reads data ignoring locks)
- READ COMMITTED (read data that have been committed)
- REPEATABLE READ (re-read data consistently)
- SERIALISABLE (avoid any type of transaction anomalies)
In the past, for very opportune reasons, some RDBMS vendors has claimed that those isolation levels are inefficient, because they need to locks data in pessimistic mode (locks are placed before reading or writing) and this mode is subject to data overcrowding.
So some vendors decided to use an optimistic mode of locking, that take a copy of the data before doing anything to be out of the scope of concurrent accesses, the time to read and write data… But this technic, sued in Oracle and copied by PostGreSQL in not the panacea…
- First is does not guarantee that your process will reach the end… If someone has modify the data you wanted to modify also, you loose your work! (« loss of update » transactional anomaly)
- Second, copying the data needs to have some more resources than working on the original data.
Finally, the technical solution chosen for the MVCC of PostGreSQL (for duplicating rows) is the worst of all the RDBMS…
- in Oracle, the transaction log (undo part exactly) is used to reads the formerly rows. No more data are generated for this feature, but the remaining part of the transaction logs can growth up if a transaction runs a long time;
- In SQL Server the tempdb database is used to keep the row versions. Some more data, out of the production database is generated and quickly collected (garbage’s) to liberate space. The tempdb system database has a particular behavior to perform this work. Recently (2019) SQL Server add the ADR/PVS mechanism to accelerate recovery and when this feature is activated, the row versions can be stored in specific files relative to the database.
- In PostGreSQL, all the different versions of the table rows are kept inside the data pages of the table and reside in memory, when data are caching, then is written on disks, causes table bloats and by consequent memory pressure, until a mechanism call VACUUM proceed to sweep of the obsolete rows.
This VACUUM process is well known to be a plague, and generated locks and deadlock a lot! Some customers end up stopping the data service in order to perform such maintenance, which in practice, is not compatible with large, highly transactional databases and 24h/24 operational state. Even with the recent parallel vacuuming that I suspect to cause even more deadlocks .
SQL Server is known to be the only RDBMS to have simultaneously the 4th transaction isolation levels and can be set in pessimistic of optimistic locking. Pessimistic mode offers the advantage of taking less resources and guarantee the finalization of the transaction, with the disadvantages of waiting because of blocking.
PostGreSQL doesn’t have the possibility to use the 4 transaction isolation levels and do only the optimistic locking in the scariest way…
And the worst of all is that for an UPDATE, PostGreSQL act as a DELETE followed by an INSERT…
What are the environment and stack differences between PostgreSQL and SQL server? Compare the environment and stack in PostgreSQL vs. MSSQL
The author seems to want to confine SQL Server to the Microsoft world, which in fact is not true.
- First, SQL Server came into the world of LINUX there in 2017.
- Second, SQL Sever is very used with LINUX Apache, Java and PHP clients.
- Third, SQL Server runs, in multiples clouds (Amazon, Azure…), multiple virtualizers (HyperV, VMWare…) and Docker.
- Fourth, SQL Server has integrated Python and R languages as a full part of SQL Server (that PostGreSQL did not…)
What are the 40 hidden gems that SQL Server have and PostGreSQL do not have ? Compare the lack of PostGreSQL vs MSSQL
This paragraph is of my own! of course paid in a way or another by EDB do not write such a malicious topic…
1 – Compliance to the SQL standard
PostGreSQL has claim by the past to be the RDBMS the most compliant to the SQL ISO standard. It was perhaps true… at the old times! But actually no.
The most conformant RDBMS are DB2 and SQL Server!
Some example must be done:
- SQL identifier must have 128 characters length. This is true in SQL Server. Not in PostGreSQL is limited to 63 characters length for SQL names.
- SQL ISO standard use in the ORDER BY clause an OFFSET … FETCH while PostGreSQL use a LIMIT … OFFSET!
- Pessimistic locking mode is the default standard (and READ UNCOMMITED must be able to be activated). This is true in SQL Server. Not in PostGreSQL that only do optimistic locking.
- MERGE SQL statement has been specified since the 2003 version of the SQL standard and is a part of SQL Server, but had never been released in PostGreSQL.
- Temporal tables has been defined in the 2015 version of ISO standard SQL and they are available in SQL Server since the 2017 version. PostGreSQL use a an abominable ersatz, unusable: none of the SQL temporal operator has been implemented…
- SQL standard make a big distinction between PROCEDUREs and functions called UDF (User Defined Function) in the SQL standard. MS SQL Server respects it while PG confuses procedures and functions, that causes a great lack of security (a user can create a UPPER function that discards data because of the overloading code strategy…).
- Creating a trigger needs a single statement in the standard and SQL Server too, but in PostGreSQL you have to code 2 distinct objects.
- The DataLink ISO SQL standard way to store files under the control of the database had never been provided in PostgreSQL, while SQL Server had it since the 2005 version un the name of FILESTREAM.
- And probably the most confusing problem is that some PostgreSQL functions have the same name as a standard function but does not at all do what the standard provided for.
As developments progress, PostGreSQL moves further and further away from the SQL standard, making portability more difficult …
2 – Stored procedure that returns multiple datasets
One feature I like very much when designing a website is the ability of the Microsoft SQL Server stored procedures to returns multiple result sets in only one round trip… If you consider performances, you will see that the major part of consuming time is due to round-trips. Reducing drastically the number of round-trips results in better performances and reduces contention and of course deadlocks…
There are no possibilities in PostGreSQL to have PG/PL SQL routines that returns many datasets to the client application…
MARS (Mutiple Active Results Sets) is another feature that PG does not have and allows applications to have more than one living request per connection, in particular you can execute other SQL statements (for example, INSERT, UPDATE, DELETE, and stored procedure calls) while a default result set is open and can be read.
3 – Automatic missing index diagnosis
SQL Server is the only RDBMS to provide a full diagnosis of missing indexes. This is the case since the 2005 version! It is therefore possible to improve performance very quickly. I remember that at one of my clients we divided by 20 the average response times of queries in less than half a day by creating a hundred indexes where SQL Server had diagnosed more than 300 missing!
There is no index diagnosis tool in PostGreSQL and you must enable a tracking tool to record query performances, then analyze manually thousands and thousands of queries and try to create the most relevant index on every case. Such a work is very time consuming and the productivity is very low and frustrating for the DBA!
4 – Storing file as « system » files under the RDBMS control
Another feature I like very much is the concept of FILESTREAM widely use for SharePoint. This is a standard ISO SQL feature called DATALINK(SQL:1999), rarely implemented in DBMS…. FILESTREAM allows you to keep the files that you wanted to store in a database, in the OS file system (out of the table), but under the transactional responsibility of the RDBMS! This makes it possible to always have the files (like pictures, pdf and so on) and the data of the tables in a synchronous manner, and in case of rollback of the transaction, the insertion of the adjoining file is also invalidated. In the event of a backup, even for partial backups that are entirely possible, the FILESTREAM files are collected in the backup process and restored during the restore without any loss, which no RDBMS today guarantees, not even Oracle!
One extension of FILESTREAM is the FileTable concept that is a two faces mirror of the Windows file system… Creating a FileTable at the entry point of the Windows file system, causes a dual interface for the files stored: one face will manage files in Windows the other will manages files in SQL Server!
SQL ISO DataLink feature or similar does not exists in PostGreSQL.
5 – A transaction logs for each database
Microsoft SQL Server use one transaction log per database. If you have 100 databases, you have 100 different transaction logs plus some transaction logs for the system database, especially for tempdb database that is used for temporary objects (tables…). And if you use FILESTREAM, a special transaction log is added only for the transacted input/output of the files stored under the control of SQL Server…
PostGreSQL use only one transaction logs for all the concurrent databases inside which all the transaction is written. This result in contention when accessing disk IO to write the transaction, which is a heavy brake for performances. Many other problems occur because of this behavior in backup processes, log shipping and streaming replication when there is a lot of databases in the PG cluster…
6 – Parametric read-write views
Online table’s UDF (User Defined Function) does not exists in PostGreSQL. Those type of functions are literally « parametric views », and can be used to read data with some function arguments, but also to write (INSERT, UPDATE, DELETE) the underlying tables.
They are defined such as :
CREATE FUNCTION MyOnlineTableFunctionName ( <list_of_variables> )
RETURNS TABLE
AS
RETURN (SELECT ... )
7 – Database snapshot
Sometime you need to have a readable copy of a database, containing the values of the data at a specific time. This is possible with the concept of the « database snapshot« . Creating such object is easy and immediate, whatever the database volume is.
Database snapshot does not exist in PostGreSQL.
As an example, the purpose is for enterprise reporting at a stable time or developer’s tests that wand to compare values before and after a big batch process, and can restore the « before » value with a RESTORE FROM SNAPSHOT.
8 – Temporary tables
In SQL Server, all the temporary objects and of course temporary tables, are created in a dedicated database called tempdb. This system database gain to be stored separately on a very fast storage device like Intel Optane or NVMe or, to get even more performance in the form of « Memory-optimized tempdb metadata », provided you have enough RAM.
This database is especially designed for very fast transactions and data movements:
- parallelism is systematically active and storage reside on multiple files;
- a specific garbage collector does not erase too fast unused tables in case of reuse.
PosteGreSQL does not have a special DB to do that but you can specify a distinct path to store temporary objects with the command:
|
1 |
alter</code> <code class="sql plain">system </code><code class="sql keyword">set</code> <code class="sql plain">temp_tablespaces = </code><code class="sql string">'...my path for temp table...' |
Of course, PostGreSQL does not have « in memory » feature, even for temp tables…
9 – Temporal table…
The concept of temporal table (not to be confused with temporary tables) as been fully specified by the ISO SQL Standard and consists to add:
- timing intervals for transaction periods to the rows of the table (2 columns with UTC datetime that can be in a hidden mode, e.g. the column will not appear when querying with SELECT *)
- a history table in which you will find older values of rows (after every update and delete)
- many operators (AS OF …, FROM … TO …, BETWEEN … AND …, CONTAINED IN …., and finally ALL) to retrieve values at different points or periods of time.
History table can be created in a « in memory » table in SQL Server. If not, all the data in the temporal table is stored in a compressed mode.
The solution that PostGreSQL offers for temporal table has many drawbacks:
- the design of PostgreSQL temporal tables has nothing to do with the SQL standard…
- In PostGreSQL, temporal table uses triggers to generate all this stuff, resulting in poor performances and many locks;
- PostGreSQL has no data compression mechanism to save data volume and execute query faster when you query the history table;
- the interval, that is not compound of 2 datetimes is hard to index and results in poor performances when queried;
- hidden the interval columns is not possible in PostGreSQL, so you cannot add it in software vendor’s databases;
- None of the temporal SQL operators has been integrated into the code….
In fact PostGreSQL temporal solution is a ridiculous ersatz of what you can have with the standard, without performance and is strictly unusable!
Another manner of dealing with temporal information is the one by Dalibo called E-maj… This contrib, close to the Oracle concept of flashback queries (but enrolling multiple objects), use some heavy triggers and costly logging tables, and does not support any schema change! Off course it is also far away from the standard SQL way of doing it…
Regarding Microsoft, SQL Server stores history table in a compressed way with a special index type called TSB-tree optimized for temporal multiversion data.
10 – XML
The implementation of XML in SQL Server is a gemstone! In PostGreSQL XML functionalities are poor and offers paltry performances
First you can reinforce the XML type of documents stored in an XML column by a XML schema collection. Each element of a XML collection is a XML schema doc, that define the XML content of document to be stored. If no corresponding XML schema is found in the collection, the XML document will be rejected like any other SQL constraint! There is no way to add constrained XML documents in PostGreSQL…
This type of constraint speed-up the information retrieving because it can translate path expressions into efficient SQL, even in the presence of recursive XML schemas.
Second, dealings with XML in table’s columns is easy because SQL Server use XQuery, XML DML and XPath2 with five methods (query, value, exists, modify, nodes). PostGreSQL only use XPath1, which is a severe limitation to manipulates XML data.
Third, modifying a data inside a XML document stored in a table, is easy with the modify method, that only changes the appropriate information and not the all content of the XML document as PostGreSQL do!
Fourth, PostGreSQL has no way to index XML stored documents… Indexing XML document is one of the most achieved feature in SQL Server, and one of the most simple!
You first need to create a primary XML index that serves as a « backbone » for other indexes and already provides significant gains in access. You can then choose to implement one, two, or three of the other specialized indexes for PATH, for VALUE or for PROPERTY…
The Microsoft research paper on this topic is available at these URLs:
https://ecommons.cornell.edu/bitstream/handle/1813/5661/TR2004-1961.pdf;j
https://www.immagic.com/eLibrary/ARCHIVES/GENERAL/MICROSFT/M040611P.pdf
Tell my why the PG staff cannot apply such technics in the PostGreSQL relational engine?
And finally, XML document inside a table column stored as XML or BINARY datatype, or outside the table via FILESTREAM, can be fulltext indexed…
11 – Trees stored in path format
SQL Server comes with the hierarchyId datatype which allows to store a tree in path mode and publishes manipulation methods to do so. No such tree facilities exist in PostGreSQL except the ltree contrib which is in its infancy and is roughly 15% of what SQL Server is doing about it.
To be honest, hierarchyId is not my favorite solution. I prefer to store trees as intervals, which is clearly the fastest way to do so.
12 – Custom aggregate function
The reason why you cannot define aggregate function directly in Transact-SQL is that SQL Server cannot parallelize the execution of UDFs. So, to empower the running of such functions, they intelligently decided to allow the creation of theses objects in SQL CLR (.net), with some pre programmed methods to facilitate the multithreading code.
Splitting the function execution in multiple threads is done by the « Accumulate » method, then the « Merge » method finally merges the multiple results of the different threads into a single one.
There is no way to create custom aggregate function that executes in parallel in PostGreSQL…
13 – Dynamic Data Masking
This SQL Server integrated feature allow you to masks data with various functions which is a great use for the GPDR. PostGreSQL does not have any free dynamic data masking functionnality, but there is a project call PostGreSQL Anomymizer which is at an early stage of development and should used carefully. Also paid versions exists, like DataSunrise Data Masking for PostgreSQL or in the DBHawk tools.
14 – LOGON trigger
A logon trigger is very useful when you want to control who accesses the instance (cluster in PG words) and the database and also to limits the number of users using the same login.
Logon triggers is embryonic in PostgreSQL.
More precisely, there is a contribution, with some drawbacks, like the needs for a systematic public permission… What a lack of security!
15 – Impersonate
Microsoft SQL Server has two levels of impersonation: at the session level and at the routine level (procedures and triggers). PostGreSQL has only a session impersonnalisation but PostGreSQL cannot impersonate the execution of a routine which is a great feature to trace the user activities with many technical metadata when usually there is no grant to the user to access this information especially for use under the GDPR. Also this feature is a great help to code routines (procedures, triggers..) wich some extra privileges that, ordinary, the SQL user does not have. In this way, the codet is closer to what we do in object oriented languages…
16 – Service broker, a data messaging system
While application have SOA (Service Oriented Architecture), which means service running and cooperating by sending messages, this architecture can be set down to the database layer… That’s SODA (Service Oriented Database Architecture)…
Such a system is coded in SQL Server under the name of « Service Broker » is made of queues (which are specific tables), services (to send and receive messages), conversations (to manage a thread of requests and responses)… Off course to manage it over HTPP, you have to deal with HTTP endpoints, contracts, routes and to encrypt your data…
There is no equivalent to Service Broker in PostGreSQL to transmit data messages from an cluster to one another with routing, serialization and transaction.
17 – Data and index compression
Another very unfortunate lack in PostGreSQL is the absence of data and index compression. SQL Server have several modes for compressing data:
- Table/index compression with two modes: rows or pages
- Using columnstore index, that can compress the whole table (clustered columnstore index) or only one index (about 10 times less volume)
Of course, compressed index does not need to be decompress to seeks the data.
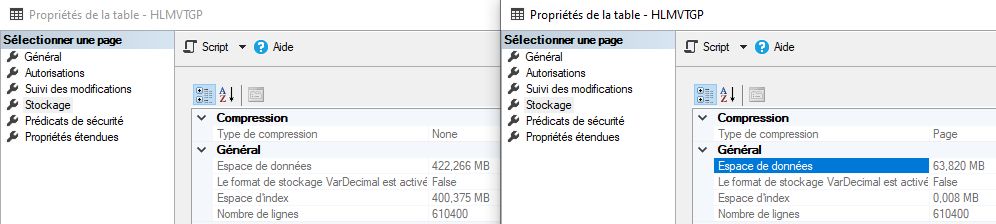
SQL Server data compression effects (same data, 6.6 times smaller)
18 – Resumable indexes
When dealing with very huge tables (hundreds of Gb…) one big problem is the duration of indexing such tables. Even if you are in an ONLINE mode to create indexes, some indexes can take a very long time to do. If the instance is overloaded at sometimes, you will need to cancel the CREATE INDEX process.
In SQL Server there is another intelligent way to process such a problem, called « resumable indexes »…
- First you need to create the index with the ONLINE and RESUMABLE options.
- Second, at any time you can stop the CREATE INDEX and preserve the work done with the command that ALTER INDEX … PAUSE.
- Third you can restart the CREATE INDEX from the point is was, with the command ALTER INDEX … RESUME.
Another possibility is to create the index with the MAX_DURATION options. When the CREATE INDEX command exceed the amount of time specified resumable online index operation will be suspended.
There is nothing equivalent like the resumable index operation in PostGreSQL.
19 – Page restauration
Before restoring the whole database, in the case of some damaged pages, you can try to recover those pages by retrieving them into the different backups. This operation is feasible via the BACKUP command. In Enterprise version, this process cans be executed in the online mode.
When using the Mirroring/ AlwaysOn high availability system, the damaged pages are automatically repaired…
PostGreSQL does not have any possibility of page repair! When you lose some data in a table page, you are condemned to restore the full backup…
20 – Intelligent optimizer (« planer » as they call it in PG)
Some more extraordinaries features have been definitively appointed in SQL Server 2019 for the database engine performances under the term of Intelligent Query Processing:
- Scalar UDF Inlining: scalar UDFs are automatically transformed into scalar expressions or scalar subqueries that are substituted in the calling query in place of the UDF operator. The result is a spectacular gain of performances for some classical UDF!
- Memory grant feedback: when the amount of reserved memory for a query has been over evaluated, the optimizer reduces the size the next time a similar query will be executed. The result is a gain of cache in memory for much more data and client operations.
- Batch mode on row store: usually algorithms in the execution plan of a query are reaching rows one by one. In batch mode the qualified rows are retrieved in a single step that involve thousand rows. The result is an important gain of performances on big tables.
- Table variable deferred compilation: due to the optimization process a table variable cannot have a correct cardinality estimation. For instance, PG estimate to 100 the rows that will be in such object. From now on SQL Server stops the execution of the query just before filling the table variable, and readjust the remaining estimated query plan to be accurate and much more performant that the formerly first estimated plan. The result is an increasing gain of performance when you use table variable.
- Adaptive joins: in some cases of heavy volume of data, where joins cannot be estimate in an accurate manner, an adaptive join is created, constituted in fact in two joins algorithms, and the final choice of the algorithm to joins the two datasets will be choose after a first read done in the smallest table (in terms of cardinality). The result is a faster join technic in some heavy queries.
- Automatic plan correction : When a plan regresses due to plan changes, previously-executed plans of the same query are often still valid, and in such cases, reverting to a cheaper previously-executed plan will resolve the regression.
All those features combined with compression, vertical indexing (columnstore index) and automatic parallelism, give to the SQL Server engine, the most powerful RDBMS of the world (even Oracle does not use vertical indexes for OLTP workloads).
As an information, PostGreSQL only have 3 join algorithms where SQL Server has 5 (nested loop, has, merge, union and adaptive…).
At the opposite, the PostGreSQL query « planer » (why don’t you say query optimizer? Because it does not optimize at all?…) reveal that it is unable to do a good job, when queries have a great number of join or subqueries. Why? The optimization rules of the PG planer are heavy consumer of resources (exhaustive-search) and a threshold has been defined (default value is 12 joins) to switch to a more sophisticated algorithm called GEQO… but the PG staff have emitted some criticism about there own solution (GEQO): « At a more basic level, it is not clear that solving query optimization with a GA algorithm designed for TSP is appropriate« …
Facing the facts, optimizing complex queries in PostGreSQL is a nightmare!
Even with classic queries the PostGreSQL optimizer can be faulted due to poor MVCC (Multi Version Concurrency Control) handling. In this user case from StackExchange :
Postgresql not using index on WHERE IN but works with WHERE =
We see that, when the subquery is introduced by the equal operator the PG planer use an index. And when the operator is a « IN » no index is used… But after cleansing the phantom records left in the data pages with the VACUUM process, index is used in both cases… Of course, it is impossible in a production environment to have fun triggering the « VACUMM » process all the time in the hope of obtaining an adequate execution plan!
Much more stupid, PostGreSQL optimizer (pardon, « planer ») is unable to understand that a constant doesn’t change its value when running the query… As a test, you can compare that the time consumed for a SELECT COUNT(*) and a SELECT COUNT(true) – and the last one is using a constant – reveal that the second form of the query runs longer ! All other RDBMS detects he constant and run the query with the same duration for both patterns.
21 – Query hints
Query hints: even if it is bad (and really I think so!) the possibility of using SQL query hints to impose an algorithmic strategy on the optimizer is clearly a good transitive solution to solve difficulties when the optimizer goes wrong… It is also a solution offered by the paid version of PostGreSQL delivered by EDB!
SQL Server offers two different hints: table hints and query hints.
The proponents of free PostGreSQL categorically reject this approach, but the presence of hints in EDB makes me think that it is more by protection of a market than by stupidity …
In SQL Server there is many ways to deal with query hints:
- adding hints directly in the SQL text of the query;
- adding a « plan guide » that adds the hints directly in the SQL text of the query on the fly (very interesting when you have an application coming from a tormented editor…);
- some hints can also be enabled at the database level or the instance level (Trace Flag);
- analyzing bad and good plan versions of the same query and decide to chose the most improved, even with hints, which in SQL Server is the role of Query Store.
In PostGreSQL there is only a possibility to enable some hint at the session or the cluster level, and this approach has severe limitations: no way to enable the hint for one query and not the other, no way to add a query hint on the fly, which is the only way to correct bad plans when they are in a vendor application!
22 – Query plan analysis
Analyzing an execution plan for a query can be done in SQL Server by the Query Plan visualization and the plan comparison tool.
The pauper tools that offers PostGreSQL for visualizing and comparing query execution plans are iron age dated, comparing to what SQL Server Management Studio (SSMS) is able to do!
Not only can you see in what step of the execution plan your query is, but SSMS can also give you the differences between two similar execution plans.
Some full addons like SentryOne Plan Explorer (free tool) reveal quickly the bottlenecks of query plan by a color code that is dark red for a heavy step…
Another possibility is to see, the query execution plans running with « Live Query Statistics« :
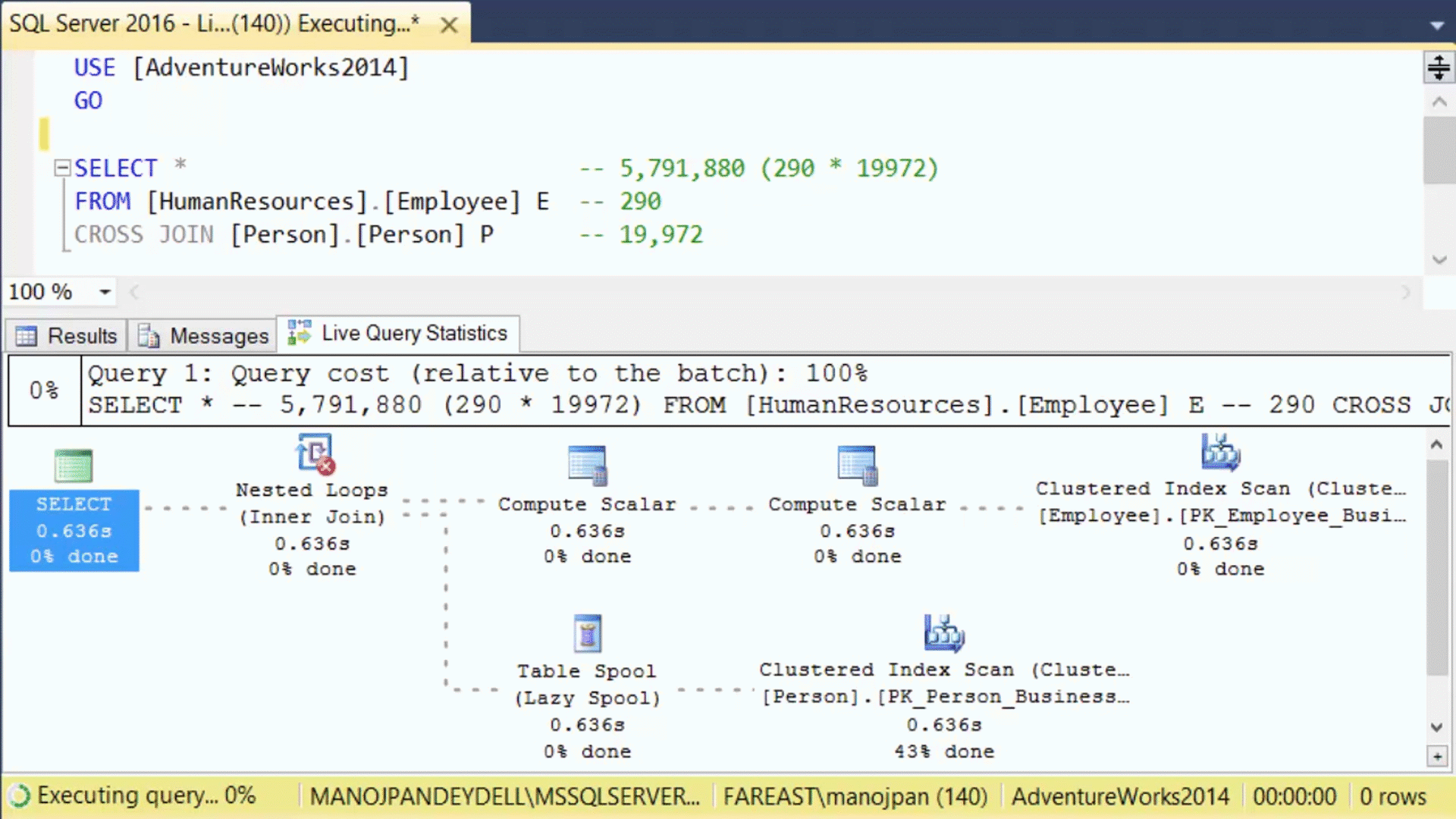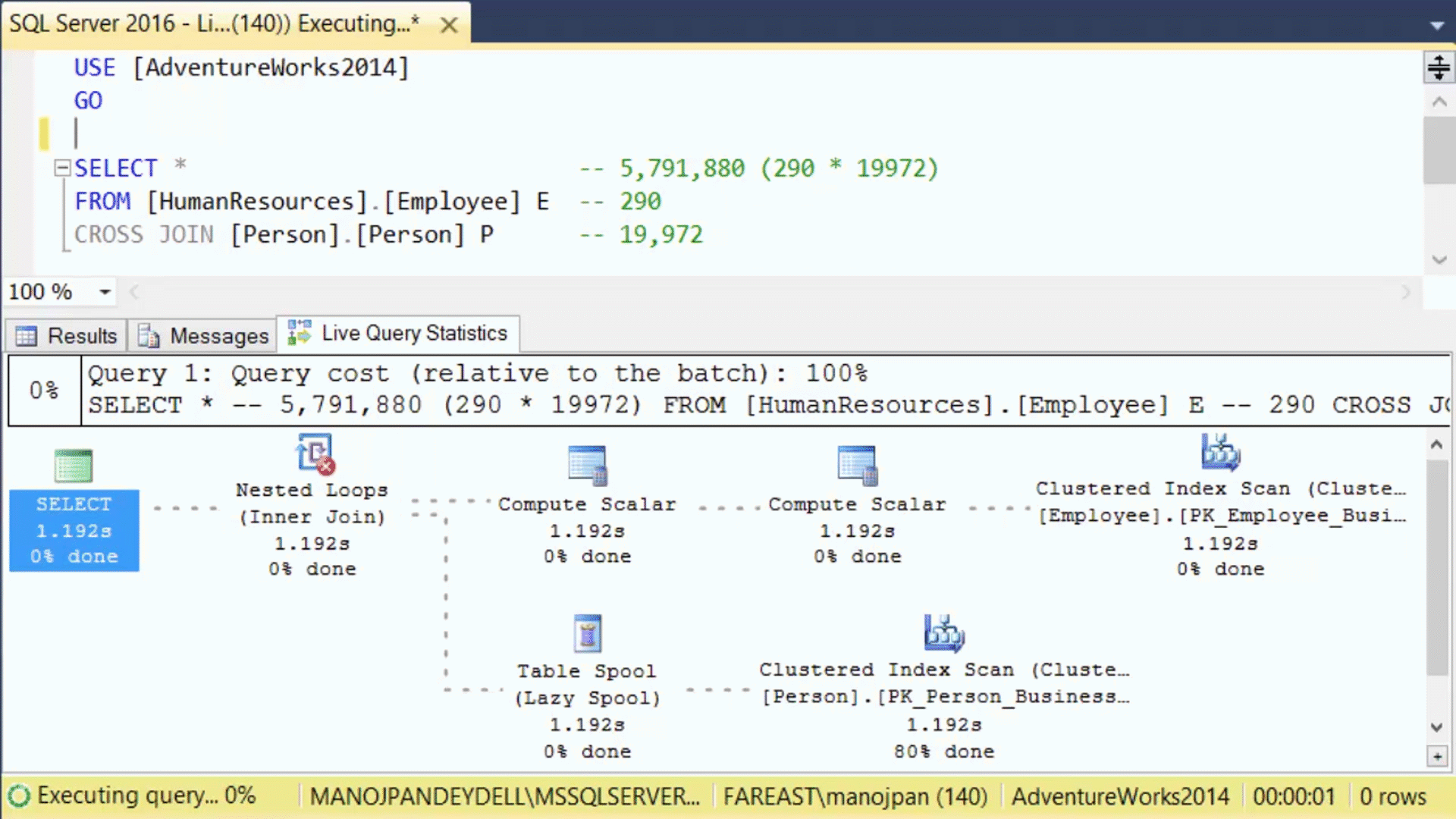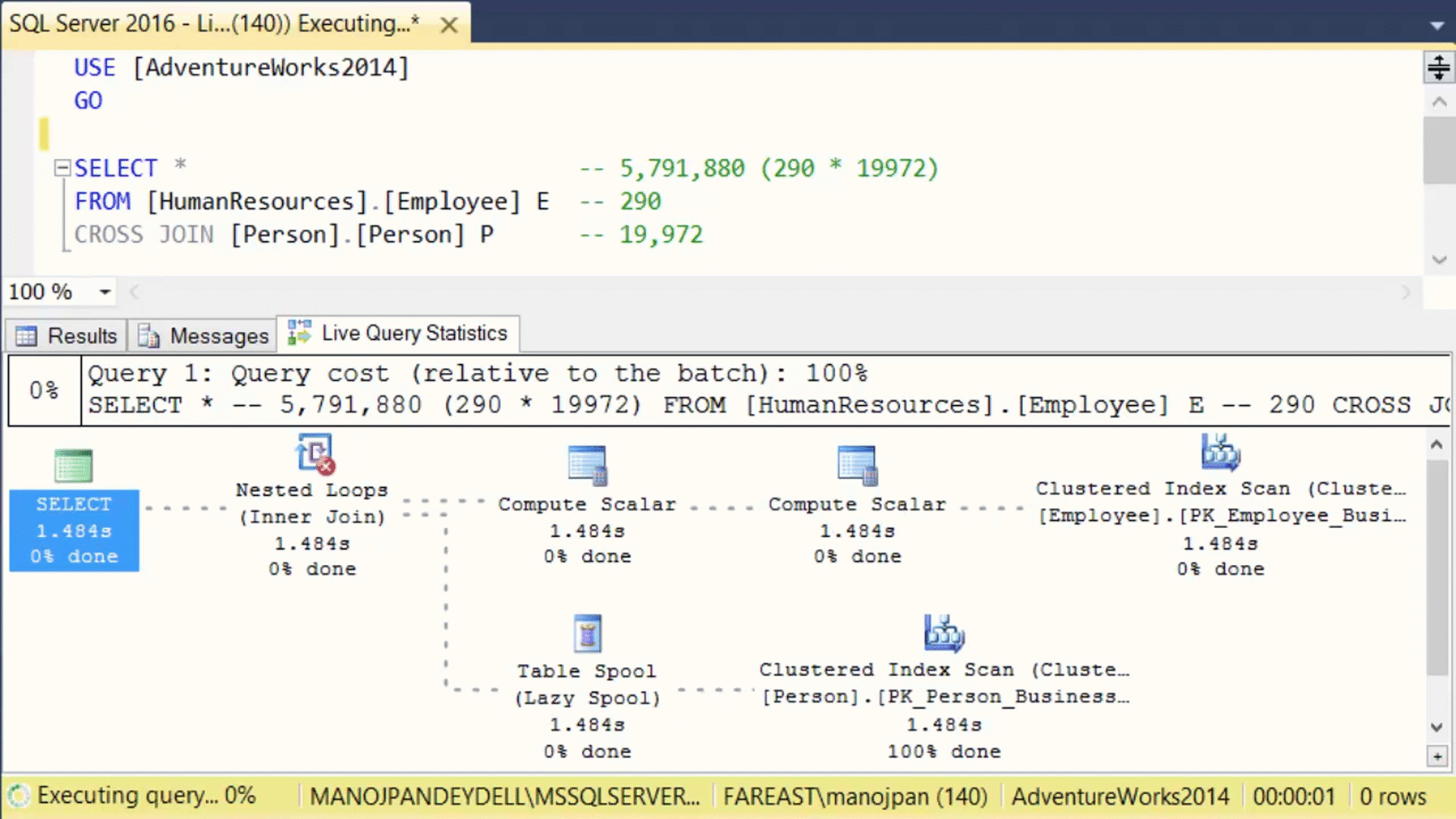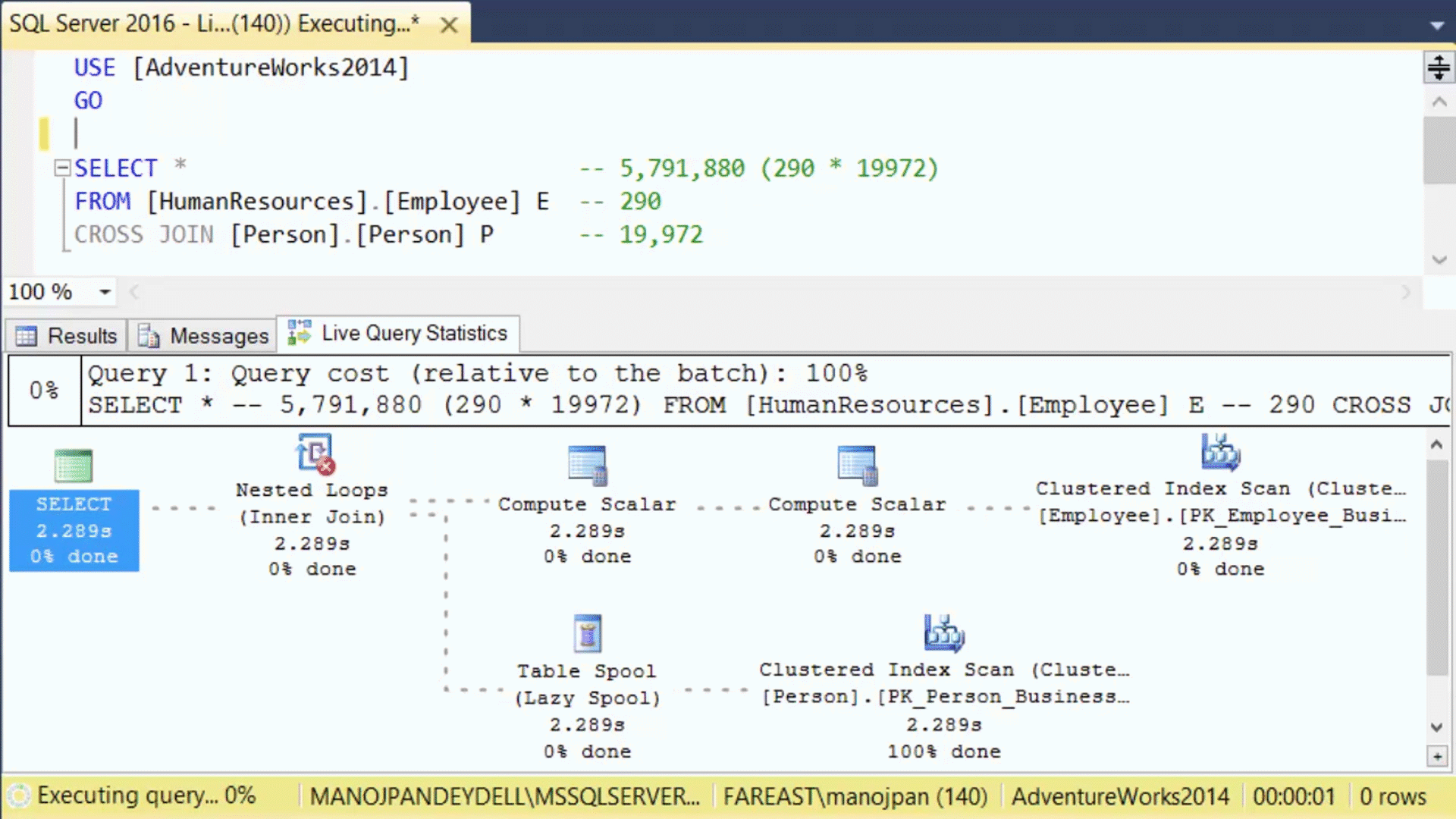
Query execution plans running with « Live Query Statistics » (with the courtesy of Manoj)
This is very useful when you are executing very long queries and wanted to know what is the steps actually running…
23 – Policy based management
If you want to automate some policy of management you can use this feature to make a continuous or scheduled check of rules that applies to some « facets » (instance, database, table…) of SQL Server. As an example, you can be informed, daily, if there is a database, newly created, that has not been backuped.
There is no tool in PostGreSQL that facilitate the implementation of management rules for the DBA.
24 – managing data quality
SQL Server have two distinct modules to manage data quality:
DQS (Data Quality Services)
MDS (Master Data Services)
There is nothing to manage data quality into PostGreSQL.
25 – Change Data Capture
Many corporate OLTP databases require that certain data to be transposed into an ODS or data warehouse. To identify the lines that have been inserted, modified or deleted during the time necessary to refresh the DW or the ODS, it is necessary to have a reliable tool so that the target base is only supplied by a data differential rather than a total reconstruction…
SQL Server has two tools for this:
- Change tracking
- Change Data Capture
PostGreSQL does not have any built-in similar tool to do that, so you doom yourself to rebuild your DW or your ODS from scratch!
Of course, you can use a tiers software to do it (Kafka as an example).
26 – Transparent Data Encryption
One major feature to deal with GDPR is the Transparent Data Encryption. This feature encrypts the whole database (date files and transaction logs, and to avoid any lack in this process, encrypt the tempdb database too). So, stealing any part of the database, even a backup, won’t do any good… This system has a very few performance impacts on the data process, because the encryption is made only when physical IO are needed. To do that, you need to manage internally (inside the RDBMS) the IO executed on the file, that PostGreSQL don’t.
PostGreSQL does’nt have anything such as Transparent Data Encryption.
27 – Database/server Audit
There is one possibility of database auditing in PostgreSQL (pgaudit). But the limitations to the database scope (no full server scope) and the fact that it is not possible to filter on columns for tables or view, nor on user account, produces an astronomical amount of data in which you will spend hours to find what you want.
Also the database audit can be stopped by a malicious strategy (e.g. filling the storage disk where reside the audit file to stop the audit process) while PostGreSQL continue to serve the data. On the contrary, SQL Server can be stopped when the audit process is unusable…
PostGreSQL’s audit solution has severe limitations that make it difficult to enforce GDPR in addition to a few security holes.
28 – Resource governor
The resource governor: is a very interesting feature when some users are high consumers of data while other one needs to be served quickly. You can define, by SQL profiling a quota of disk, RAM and CPU, and in order to prioritize processes, your different categories of users…
There are no possibilities in PostGreSQL to quota the resources of certain users
29 – More cache for data than the limit of the physical RAM!
Buffer pool extension: no enough RAM for caching data? Think to set 4 to 8 times your actual RAM to a second level of cache with this feature. Of course, it needs a sort of RAMDISK, like NVMe or Intel Optane…
There is no possibilities to create a secondary level of cache in PostGreSQL.
30 – Investigate inside the DBMS engine and further
The extraordinary collection of Data Management Views (DMV) helps you to collect, understand, tune, fix, analyze… everything you want inside and outside SQL Server when running in real time. 278 views or inline table function can be queried to see what SQL server is doing or has done…
A list of these views can be download in pdf format on the Quest website:
https://www.quest.com/docs/ql-server-2017-dmv-dynamic-management-views-poster-infographic-26735.pdfSQL S
278 management view in SQL Server… A big difference compare to the 27 views of the PostGreSQL « Statistics Collector »…
31 – EXtended Events
Extended Events is a lightweight architecture that gives the possibility to investigate at a high level in the system to understand what happen while SQL Server is running.
No high-level fine grain investigation is possible in PostGreSQL. Some contribution can do a few things but they are disparate, and synthesizing all the metrics of the different contributions is not an easy task as the different formats of the data collected are heterogeneous … Of course, the sharpness of the investigations given by the SQL Server EXtended Events has nothing to do with the roughness of the possible analyzes in PostGreSQL
There is absolutely nothing equivalent to EXtended Events in PostGreSQL to troubleshoot at a high level.
32 – Database file security
While the SQL Server engine database is running there is no way to copy or drop the files of the database, because they are hooked by SQL Server process and protected by Windows (note that this feature is not available in Linux which have a different behavior). In PostGreSQL, that creates many many files for a single database, destroying a data file or an index file is easy and nothing is alerting the DBA, except that some events written in the error file! But it is too late…
33 – Easy tuning
SQL Server has always claim to be tuned automatically. So, there is few parameters to modify, and essentially when you are installing SQL Server on a machine, to deal with RAM and parallelism. 85 options are configurable but some of them are obsolete (but maintain for retro-compatibility feature) and some other automated (nothing to do).
When you modify many parameters simultaneously, SQL Server verify the concordance, except if you execute the command in WITH OVERRIDE option. In facts only 20 options are really used, and in 99% of the instances, only 5 options are configured
PG offers you 315 parameters to deal with, and no verification is made to help you to do no mistake!
34 – Monitoring tools
As we say in French « do not shoot the ambulance« . PGAdmin is the worst query tool ever. Even MySQL has a better tool! SQL Server Management Studio is, without a doubt, the best query tool! Some vendors has copied it for their solutions, like Quest with TOAD !
{kind=link}
{kind=link}
Many heavy enterprise monitoring tools exists for SQL Server like SentryOne SQL, Red Gate, Idera, Apex, Quest Spotlight… or lighter like Solar Winds, Paessler, DataDog, DBWatch, SpiceWorks… and sometime free like Kankuru !
Rare are similar monitoring products for PostGreSQL : Solar Winds, Paessler, DataDog… does not run at the same level that Sentry, Red Gate or Idera…
35 – Hot hardware escalation
SQL Server on Windows accepts, with a specific hardware design (HP, Dell) to have some more physical resources (CPU, RAM) without switching off the machine…
PostGreSQL has not been designed to acquire more physical resources without being extinguished beforehand.
36 – Documentation
Microsoft SQL Server is the most well documented RDBMS in the world. PostGreSQL documentation is very poor especially in real productive examples of code…
Comparison of documentation size between PostGreSQL and SQL Server
37 – Recovery models
SQL Server can log transactions in three different modes:
- FULL: everything is written into the transaction log file;
- BULK LOGGED: some reproducible parts of transactions are not logged (CREATE INDEX, SELECT … INTO…, BULK INSERT…);
- SIMPLE: same as BULK LOGGED, but the transaction log is automatically purged.
In FULL and BULK LOGGED the transaction log keep all the stuff until a BACKUP LOG that purges the transaction log is done. Simple recovery model is very fine for OLAP databases while OLTP needs FULL or BULK LOGGED.
Nothing equivalent to those recovery models exists in PostGreSQL…
38 – UPDATE joins
In case of UPDATE with many tables MS SQL Server can use a syntax very close to the SELECT. This syntax works as follow :
Write a SELECT with all the joins you want an put into the SELECT part, the columns that needs to be modify and the value that each columns to modify will have, then add a first line with the key word UPDATE and the target alis of the table that need the modification. Last, replace the comma by an equal sign between columns and values of the SELECT list and drop the letters LEC of the kaeword SELECT. Les us see with an example:
|
1 2 3 4 5 6 7 8 |
SELECT name, UPPER(name), category, 'customer' FROM persons AS p JOIN orders AS o ON p.prs_id = o.prs_id JOIN cities AS c ON p.cit_id = c.cit_id JOIN states AS s ON c.stt_id = s.stt_id JOIN lands as l ON s.lnd_id = l.lnd_id JOIN continent AS ct ON l.ctn_id = ct.ctn_id WHERE ct.name = 'Europe' |
Then transforming as said:
|
1 2 3 4 5 6 7 8 9 |
UPDATE p SET name = UPPER(name), category= 'customer' FROM persons AS p JOIN orders AS o ON p.prs_id = o.prs_id JOIN cities AS c ON p.cit_id = c.cit_id JOIN states AS s ON c.stt_id = s.stt_id JOIN lands as l ON s.lnd_id = l.lnd_id JOIN continent AS ct ON l.ctn_id = ct.ctn_id WHERE ct.name = 'Europe' |
This kind of facilities to writes UPDATEs does not exists in PostGreSQL, but have been add to MySQL…
39 – Storing LOBs apart from relational data
Apart from FILESTREAM for storing large files under the control of the RDBMS, SQL SERVER makes it possible to dissociate, for the same table, the storage of purely relational data from LOBs (Large OBjects). This avoids clogging the cache with large, poorly accessed data.
This is done by adding a storage space to the database and specifying the TEXTILAGE_ON directive by specifying this new storage, at the time of the CREATE TABLE.
Of course PostGreSQL TOAST can do this, but it adds compression, which is clearly actually out of date since still image, video or sounds are frequently internaly structured with a specific compression algorithm (jpeg, mp4, mp3…). Of course you can use the PG_DETOAST_DATUM_PACKED to avoid compression. But you cannot indicate where the PostGreSQL TOAST table must be stored…
PostGreSQL cannot dissociates the storage of relationnal on one side and LOBs (large text, pictures…) in another side for a same table. Worst, the use of a compression state by default for all LOBs is a nonsense because the main part of LOBs are naturally compressed.
By the way, you can use COMPRESS and DECOMPRESS function in SQL Server to use compression for any data in a table.
40 – Starting a procedure when database starts
In some situations, you need to start a procedure, like a listener loop, a background maintenance task… when the SQL Server service starts.. As an exemple :
|
1 2 3 |
<span class="kwd">EXEC </span><span class="pln">sp_procoption @ProcName </span><span class="pun">=</span> <span class="str">'P_MyStoredProcedure'</span><span class="pun">,</span><span class="pln"> @OptionName </span><span class="pun">=</span> <span class="str">'STARTUP'</span><span class="pun">,</span><span class="pln"> @OptionValue </span><span class="pun">=</span> '<span class="kwd">on</span>'; |
This code will fire the procedure P_MyStoredProcedure a each time the SQL Server service will start…
Starting a PostGreSQL function right after database start is impossible in PostGreSQL…
41 – Automatic indexing
I will lie! The cloud version of SQL Server called SQL Azure has features ahead of version on premises, and offers the possibility to create automatically all the indexes you need.
On premise version will have it in few month and the internal system tables are already prepared to support them!

Automatic indexing in SQL Server
There is no way to ask PostGreSQL to automatically create the indexes necessary for the proper functioning of the database
What are the gotchas that PostGreSQL have and SQL Server do not have ? Compare the worst features of PostGreSQL vs MSSQL
This paragraph is of my own too !
1 – The plague of postGreSQL MVCC…
To ensure optimistic locking, every RDBMS must have a system that copy the data for each row that needs to be read when another client want to modify the same data. To do that, different RDBMS uses different technics… Generically this is named MVCC for Multi Version Concurrency Control.
- In Oracle database the transaction log is used to do so.
- In SQL Server, the tempdb (a specific database with it’s own transaction logs) receive the versioned rows.
- In PostGreSQL, all the different versions of the same row are clustered in the same page of the database.
The PG MVCC solution is the worst way to do it, because it has three major inconvenient:
- First, the table is naturally bloating, and this « bloatage » is increasing severely when the number of concurrent transactional operation is high…
- Second, because that pages are the minimal logical memory storage, the data cache (table and index’s pages containing rows are pin in memory to reduce IO disk access) is filled with plenty of obsolete rows, this results in the cache memory being replete with a lot of unnecessary data, pushing out a lot of data actually used.
- Third, you need to use the terrific VACUUM tool, that locks a lot and causes some deadlock crashes to clean up the memory and remove the rows no longer needed.
Details about this behavior can be found at « Is UPDATE the same as DELETE + INSERT in PostgreSQL? »
Sentry experimented a PostGreSQL crash due to the VACUUMing that causes a major outage of the hosted Sentry service…
https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres
Some customers run away from PostGreSQL for that reason. The best-known example cames from Uber …
2 – Bugs that remains from years…
I very much like this one… This query:
|
1 |
SELECT 'A' IN ('A' 'B'); |
Throw an exception… ERROR: syntax error on or near « ‘B’ »
If you arrange the query text differently, you have a surprise…
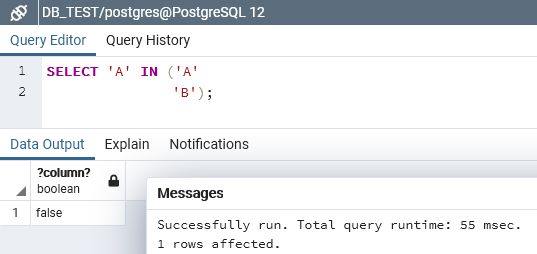
This bug is in PG since almost 2014…
The consequence is simple: Never indent your query texts in PostGreSQL! How easy it is for debugging…
Among the bugs, this other curiosity that can be found in the official PostGreSQL documentation and remains from 2010:
The rewriting forms of ALTER TABLE are not MVCC-safe. After a table rewrite, the table will appear empty to concurrent transactions, if they are using a snapshot taken before the rewrite occurred
3 – Data casting
Many dynamic typing are incorrect in PostGreSQL. When you use a datatype combined to some other, the SQL standard ISO language specify that the resulting datatype must be the minimal combination of the different datatypes involved in the operation. This is not true in PostGreSQL… As an exemple, char datatypes combination conducts systematically to the TEXT datatype as shown in the following picture:
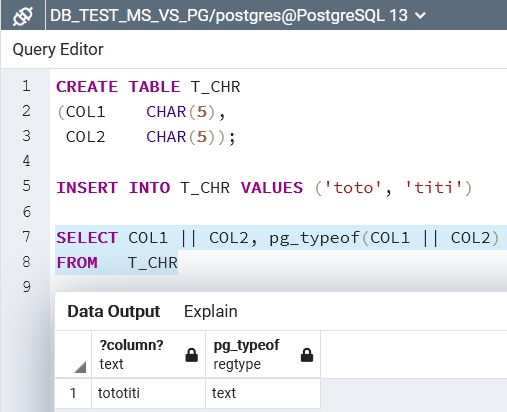
Many other data types have the same trouble. Another example came with the money datatype in PostGreSQL which is a fine mess!
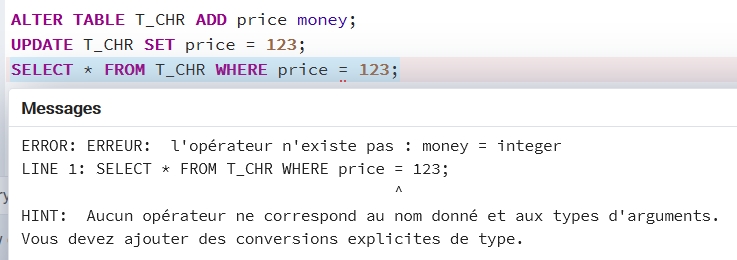 If you use this datatype, you have to explicitly cast the value! This is an incredible limitation that no other RDBMS have!
If you use this datatype, you have to explicitly cast the value! This is an incredible limitation that no other RDBMS have!
4 – The horrible performances of COUNT…
Many papers pointed out the poor performances of the COUNT aggregate function in PostGreSQL (even PG staff), performances that are often the worst of all RDBMS… This is due to a design flaw in the PG engine architecture related to the way the MVCC was made. In facts, PG needs to read all the rows in the table’s or indexes pages because the MVCC leaves phantom rows… In other databases the optimizer collects only a single integer at the header level of the data page that contains the exact number of available rows. SQL Server is merely the faster of all in many cases where COUNT is used…
Count Distinct Compared on Top 4 SQL Databases
Our previous paper pointed out that PostGreSQL was globally 100 (one hundred) time slower than SQL Server ! And sometime 1 400 time slower…
PostGreSQL vs Microsoft SQL Server – Comparison part 2 : COUNT performances
5 – The catstrophic performances of DISTINCT…
In the same filed of COUNT, PostGreSQL DISTINCT operator has some of the worst performances of all RDBMS! Just have a look on this paper that point out this disgrace of PostGreSQL « How we made DISTINCT queries up to 8000x faster on PostgreSQL »
The title of this paper speks from itself…
6 – The lack of Clustered Index (AKA IOT)
What makes « MS SQL Server » strong is that the SQL engine was built around the notion of clustered index and optimized for it. However PostGreSQL, although offering this possibility, is not optimized in this sense, quite the contrary. RDBMSs like SQL Server or MySQL are much more efficient with this technology, because they do not have to worry about the physical location of a row which can change with updates. However, changing the storage location of the row in the table always causes performance losses because all the indexes must be updated! By having a logical pointer like the clustered index (named IOT by Oracle) no update of the pointed value is to be done in any index, because this value does not change, and even less so if the clustered indexes are built on auto increments deemed to be immutable …
7 – The hard way to udpates unique values
According to rule 7 of Codd’s twelve rules about RDBMS, the capability of handling a base relation or a derived relation as a single operand applies not only to the retrieval of data but also to the insertion, update and deletion of data.
This is not true in PostGreSQL!
As a matter fact, PostGreSQL is unable to update some data when a unique or primary key constraint strengthens the values of the data…
Let us show this with a simple example:
|
1 2 3 |
CREATE TABLE T (U INT UNIQUE); INSERT INTO T VALUES (1), (2), (3); UPDATE T SET U = U + 1; |
The last query throws and error, while any other real RDBMS (Oracle, SQL Server, Sybase, DB2…) does it!
But…. PG delivers a contorted way to bypass the problem, by using a deferred transaction!
8 – Views that cannot be updated
PostGreSQL have an incomprehensible limitation about views updating. When a view is compound of several table, a simple partial INSERT, UPDATE or DELETE can be execute with every RDBMS including MySQL/MariaDB) on one of the table of the view, except on PostGreSQL, that throw an exception: « Views that read multiple tables or views are not automatically writable. »
9 – Pivot or Unpivot?
While many RDBMS have PIVOT’s feature, PostGreSQL doesn’t have the PIVOT nor the UNPIVOT operator. Off course you can do a PIVOT operation without the PIVOT key word SQL operator, but the main difference is about performances! Using a bad trick like the one you can use with arrays in PostGreSQL is clearly the poorest one in terms of speed!
10 – No ONLINE DDL
When creating or altering database object, PostGreSQL set an exclusive lock, often on the whole table, sometimes on rows concerned (e.g. FK constraints). Only a CREATE INDEX can be set online.
In SQL Server, not only the CREATE INDEX can be online, but mostly operations like adding or deleting a column or a constraint.
11 – No debug for triggers
PostGreSQL does not offer the possibility to debug triggers otherwise by adding some RAISE commands… This is quite problematic when it is known that many developers are uncomfortable with coding triggers. By comparison, SQL Server offers a real debugging tool and, in addition, you can put PRINTs command to send a message to the diagnostic console or send a complete dataset via a simple SELECT statement…
12 – Planer statistics
Managing the statistics for the « planer » to optimize a query, is very minimalist in PostGreSQL:
- there is no possibilities to compute statistics on the whole table or index in PostGreSQL, what we call FULLSCAN in SQL Server;
- there is no possibilities to control the percentage, or the number of rows, concerned of the statistics sample in PostGreSQL, for each tables, what we call SAMPLE … PERCENT or ROWS in SQL Server;
- there is no possibilities of import or exports statistics in PostGreSQL, what we call STATS_STREAM in SQL Server;
- there is no possibility to automatically recompute statistics when needed in PostGreSQL, what we call AUTO_UPDATE_STATISTICS in SQL Server. PG’s AUTOVACUUM do much more jobs but it is blocking and it searches phantom slots, not inaccurate stats. PG ANALYZE process that recompute the stats set a read lock on the table, while SQL Server does not!
- when restoring the database, all the planer statistics are loss;
- creating statistics is very very slow in PostGreSQL compare to SQL Server that’s run in multithreaded… in our tests PostGreSQL was about 10 times slower than SQL Server
PostGreSQL vs Microsoft SQL Server – Comparison part 1 : DBA command performances
Well, this last point is really one that is very important to take into consideration if you want to deal with huge tables and a heavy transactional activity in PostGreSQL!
The result of all that stuff is the bad quality of « planer » execution plan and, of course the global performances….
13 – Data encryption
One horrible feature with terrific security vulnerabilities is the way that PostGreSQL deals with encryption. In SQL Server, all the keys and certificates are hierarchically nested from the SQL Server instance to the encryption key, and needs to pass through the « caudine » forks of the database master key. So event if the database is stollen (the files or a backup) the burglar will not be able to restore it and clear the data, because the database needs to access the key at the upper level…
In PG, you must have somewhere the key in a file in the instance scope or the client application to encrypt or decrypt by pg_crypto. Do you leave your car with the keys on?
Much more, SQL Server can use an HMS (Hardware Security Module) that keep the keys into an electronic device, that can automatically be destroy in case of key rape attempt… Many health insurances use this principle.
No such system (HSM) is available in PostGreSQL!
14 – The disastrous user’s number scalability
Poor scalability: PostGreSQL has not been design for a high number of concurrent connections. Limited to 100 by default, many developers forget to think about scalability of concurrent users…
The PG staff say: « Generally, PostgreSQL on good hardware can support a few hundred connections. If you want to have thousands instead, you should consider using connection pooling software to reduce the connection overhead. »
A few hundreds? Ok! That’s gigabytes!!! Because PG uses a fair amount of memory per connection (about 10Mb).
Conversely SQL Server integrate a pooling system for many drivers (ADO, .net, PHP…)
https://miro.medium.com/max/1500/0*aoP9QjslvvSOS-jM.png
From : https://brandur.org/postgres-connections
{kind=link}
This picture shows the slowness increasing for a connection to PostGreSQL… The practical limit at never overpass is 300, meaning each connection will take about 300 ms, threshold from which users began to think that something abnormal is comming…
15 – Poor backup/restore strategies … and bugs !
- PG_dump does not generate binaries backups, but writes a SQL batch. Conversely in SQL Server, BACKUPs are binary pages of the database plus a portion of the transaction log. This accelerates backups and restore processes.
- PG_dump place a lock on the db that forbids the use of certain SQL commands like TRUNCATE or ALTER… in SQL Server there is no SQL command at the database level that have to wait because of a backup, except a new backup of course!
- PG_dump is an external command out of the security scope of the database, and you cannot give the right to a SQL user to dump some database and not the others… In SQL Server the BACKUP command is a Transact SQL Statement and can be protected in different manners to ensure a maximum of security even for DBAs…
- There is no way for PostGreSQL to check if the dump is readable and uncorrupted. In Microsoft SQL Server’s the transact SQL command RESTORE VERIFYONLY command. In fact a PostgreSQL « backup » file is not a backup but only a logical « dump » (series of SQL commands to reconstitute the database). With a real binary backup (that’s copy the data pages) like Oracle or SQL Server it is possible to verify the internal checksum at the time of the backup or at any time after. The only way to ensure that a PostgreSQL dump is consistent is to restore it …! Of course, this approach is particularly poor in production … (expensive in terms of time and volume!).
- PG_dump is not able to spread the backup file over multiple destination. Also, there is no way to parallelize backup over multiple targets. SQL Server offers BACKUPs strategies known as family backups to access a set of devices, and also the MIRROR TO option, offers you to send the backup files on, at last, three different destinations (as an example on a local directory and simultaneously a distant file share).
- Backuping a hot readable standby in PG needs to stop the replication on standby using
SELECT pg_xlog_replay_pause()which in case of a crash while running pg_dump results as the loss of the « protected » database ! This is not the case in SQL Server… even in synchronous state and automatic failover… - PG offers no strategy to do a piecemeal restoration (beginning to work with the data of the database which is still under the restore process) as SQL Server does.
- A simple PG_dump command if often 2 to 6 times slower on a database with exactly the same data as in SQL Server.
- Because The PG_dump process uses a REPEATABLE READ isolation level, Restoring a PostGreSQL backup results in a database whose data state is when the backup was initialized, while SQL Server restores the database to the state upon completion of the backup, which allows a better continuity of successive backup process.
- Optimizer stats (pardon, « planer stats ») are loose when restoring a database. You may recreate it from scratch. This may not be important for data production, but for application vendors who use PostGreSQL and need to recover customer data following an incident, this complicates the process and lengthens the time it takes to recover the database for analysis.
In this paper website « Le bon coin » says that restoring a 100 Gb data plus 50 Gb transaction log PostGreSQL database, will spend 255 minutes, which is over 4 hours. By comparison, for a similar amount of data and magnetic disk SQL Server will spend about 30 minutes…
Disadvantage of PostGreSQL dump… surprising bugs !
Because PostGreSQL is unable to execute a binary backup, but only a dump, which is a copie of the values of the rows of the table, PG_dump just consists of a data export. So literals are extracted as is, and number or dates are convert into litterals. Then SQL commands are added to recreate the structure (CREATE TABLE…) and the INSERTs.
The result is a texte file that can be interpreted as a SQL script to reconstitute the database.
But this method as a major disadvantage… Sometime combination of bytes that results in the export script can be interpreted by the reader process as non printed commands like carriage return, line feed… This will raise an error while recreating the database, like the one faced in this stackoverflow post :
PostgreSQL restore error: “syntax error at or near ”x »
16 – No internal storage facilities
We spoke about FILESTREAM and FileTable earlier that does not exist in PostGreSQL… Let’s talk about table and index storage…. In SQL Server, like in Oracle or DB2, the storage engine of the RDBMS uses internal routines to perform physical IO operations as quicker as possible. A database in SQL Server can use only one file for all objects, and it is possible to add some more files to parallelize (for a quicker access) or to ventilate data (for a peculiar purpose, read only as an example) .. On the contrary, PostGreSQL delegates all the IO operations to the OS. And because a table creates multiple files, (including indexes) the OS have to deal with an incredible number of file descriptors, which needs a lot of internal OS resources. Also, PostgreSQL is unable to have a part of the database stored in read only mode…
And PostGreSQL has no strategy to go on « In Memory » tables, except if you want to pay for the Fujitsu Enterprise version…
17 – bug in INFORMATION_SCHEMA
Some ISO SQL standard metadata views are not correctly implemented in PostGreSQL which is not a real problem, except the case you want to have the same database design in different RDBMS… But for a DBMS which loudly proclaims to be the most respectful of the SQL standard, not being able to use the INFORMATION_SCHEMA views because of such an error, seems to me to go against its philosophy.
https://www.postgresql-archive.org/Primary-key-error-in-INFORMATION-SCHEMA-views-td6022177.html
https://www.postgresql-archive.org/BUG-16642-INFORMATION-SCHEMA-DESIGN-td6156029.html
18 – The default « public » schema
While in other databases the default SQL schema is always a specific one, PostGreSQL have had the bad idea to use the « public » schema as the default for creating tables, views and any kind of routines. This, combined with the fact that functions in PostGreSQL are not really function as the SQL standard requires (UDF) and are able to writes data (which is forbidden in UDF), and do not requires the schema prefix to be used, makes an explosive combination of security lack… Anyone can create a malicious function called UPPER, placed by default in the public schema, that will destroys data in your database tables when any user will execute a query in which the code needs to capitalize some character’s string !
This design flaw has been recognized as one of PostgreSQL’s most important vulnerabilities and requires such modifications for software publishers that it should remain in the code for many more years….
In SQL Server this is impossible, because the distinction is made between procedures that cannot appear into SQL queries, and UDF which can only, reads data. Also, User Defined Functions needs to use the schema prefix to be distinguished from integrated SQL functions delivered by the editor that does not have any schema prefix, as required by the SQL Standard.
19 – Materialized view with no auto refresh
In November 1998, Larry Ellison, claims and bets a million dollars that Microsoft with SQL Server is unable to compete with Oracle about a TPC-D benchmark query on a 1 Tera byte database or it turns out 100 times faster than usual. But in March 1999, Microsoft, which has just released version 7 of SQL Server, retorted by showing that it did better than Oracle on this query. Oracle had just come up with the concept of materialized views, while SQL Server did better by delivering indexed views where the main advantage is that there is no need to refresh since these views are always synchronous with the data in the tables. Bill Gates had therefore won Larry Ellison’s bet, but the latter never paid for it!
Of course, because PostGreSQL has always aping Oracle, materialized views needs to be manually refresh… which, in practice, makes it very unusable.
The refresh process consists of recalculating all the data in the view!
In MS SQL Server, all the « materialized » views, which are called indexed views, are always synchronous to tables data and they doesn’t needs to be refresh, like any other index… And more, the optimizer can automatically substitute the results of an indexed view instead of executing the query on the tables, when query execution results are available in the indexed view.
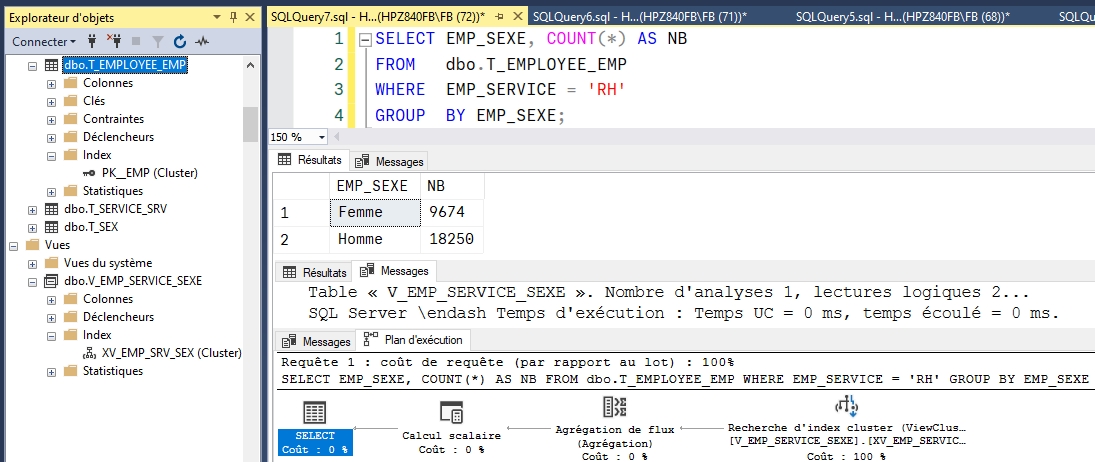
The SQL Server optimizer substitue the results of the view instead using the table
The PostGreSQL « planer » does not have the « intelligence » to substitue the pre-computed results of a materialized view if needed into a query that access equyivalent tables…
In real life, PostGreSQL materialized view are only suitable for dead data, like archives, but not for lives tables !
20 – oid or not oid… Why extra columns?
In some PostGreSQL system table you have a column named oid. In some other, you don’t see this column in the table description, but this column is returned in a SELECT *. Some other system table does not have the oid columns… Why such an inconsistency? Why are some information hidden?
Also, when you create a table, PostGreSQL add some more columns (tableoid, cmax, xmax, cmin, xmin, ctid…) that I do not want and this violates the basics rules of Codd’s relational theory! … and can cause big trouble if you want to migrate from another RDBMS : imagine that in SQL Server you have a table with a functional column named ctid… You want the same one in PostgreSQL, but you cannot!
ALTER TABLE MyTable ADD ctid INT;
ERROR: column name « ctid » conflicts with a system column name
SQL state: 42701
… Because these colums does systematically exists in all the PG table.
You will have to rewrite your complete application because of these stupid columns:
 There is absolutly no such hidden column in SQL Server.
There is absolutly no such hidden column in SQL Server.
21 – Improper use of reserved names
Some functions given by some PostGreSQL extensions have reserved names that they shouldn’t have. For instance, the widely used PostGIS, names all the function by the prefix ST_, because of the ISO SQL Standard (and OGC too) decided to define the geo functions as so… But there is a limited list of geo functions in the standard whereas PG named all the function with this prefix. This has two consequences:
- first, it is impossible to distinguish what is proper to the standard and what not;
- second, OGC and geo SQL, add regularly new functions, and the new function names can conflict with nonstandard PostGreSQL function names.
This can be a real trouble when you want to migrate queries between different RDBMS!
22 – Multitenant…. but
PostGreSQL’s bad habit of systematically wanting to copy Oracle often leads to reproducing pitiful functionality. This is the case with dblink, the prerogative of Oracle, that PostGreSQL staff stupidly reproduced, believing they were doing well.
The idea is to allow cross-database queries operating in a transversal way in different databases. for example, a join between two tables from two different databases or a sub-query carried out on a database whose data are exploited by a query from another base.
What was not abnormal under Oracle whose system only allowed to create a single database, until the arrival of the pompous « multitenant », turns out to be stupid under PostGreSQL which has been multi-base for many versions…
This PostGreSQL dblink, modelled on Oracle, allows an X-database to see and interpret, in a query, data from a Y-database. But there is a catch… Because of the dblink in PostGreSQL, data operations between these two databases are required to pass through a temporary table (often a « remote join »), which in practice is a real black hole in terms of performance.
However, it is common for software editors to create as many databases as there are customers or folders or anything else… And in the case where a common repository is needed for all these databases, as in the case where you have to cross the data from all theses databases (summary tables for example), the performance of the queries will go from slow to catastrophic!
SQL Server hasn’t needed dblink for a long time to perform cross-base queries, and more such queries are as well optimized as intra-database queries!
23 – Nested transaction
When you write multiple stored procedures, which in practice is a very good job for performance reasons, you need frequently to code a transaction for each procedure even if one procedure must call the other. Then, you have some nested transactions. One transaction inside another transaction. To solve elegantly this case, SQL Server use an asymmetric model of nested transaction :
- The first BEGIN TRANSACTION encountered in the session, sets the session status in the transactional mode (the autocommit is disabled).
- All new BEGIN TRANSACTION do nothing to the transactional status.
- The first ROLLBACK encountered in the session, immediately stops the transactional state and cancel all the works that have been done.
- The last COMMIT, corresponding to the exact count of BEGIN TRANSACTION that have been executed, save all changes made since the first BEGIN TRANSACTION.
There is no way to manage nested transactions in PostGreSQL
24 – Version compatibility
SQL Server, since the 7 version (1999), have always had a compatibility model, so, today, with the most recent version of SQL Server (2019) you can use a database build for 2008 in a 2019 instance, and this database will have the behavior of a 2008 one.
It is not rare to have a single SQL Server instance running dozens of databases with various compatibility version. This results in a very important save of money and time because managing a single instance with many databases is quicker, simpler and smart with the use of SSMS and maintenance jobs. One of our customers have more than 20 000 database on a single instance, running in different retro-compatibility models…
There is no database compatibility mode in PostGreSQL
25 – Migration facilities
SQL Server can migrate from an edition to one another (even if the targeted edition is of a lower level – from Enterprise to Standard as an example) or from a given version to a upper one. This can be done without any data service interruption by using the mirroring techniques or the AlwaysOn principles. The applications are informed that there is an alternative instance in the connection string for the mirroring technology or by the automatic redirection via a listener create by the failover cluster in the use case of AlwaysOn. This can also be used when a Service Pack (SP) or a Cumulative Update (CU) needs to restart the SQL Server services, which became very rare as time goes by…
There is absolutely no possibilities in PostGreSQL to have any migration from one version to another, minor or major, without breaking the databases service…
Another way to migrate databases in SQL Server can be done by detaching the files of the database (data and transaction log) from one instance to reattach it to one other. This operation take only few milliseconds and the SQL script is quite simple:
|
1 2 3 4 5 |
EXEC sp_detach_db 'MyDatabase'; :connect MyServer\MyNewSQLInstance CREATE DATABASE MyDatabase ON (FILENAME = 'C:\MS SQL\MyDatabase.mdf') FOR ATTACH ; |
PostGreSQL does not have such Migration facilities… pg_upgrade is close to this process but many authors do not recommend it because it’s a bit complicated and the time to do so is largely over the one you will have to do it in SQL Server…
How to Perform a Major Version Upgrade Using pg_upgrade in PostgreSQL
Upgrading and updating PostgreSQL
26 – Applying patches
Minor versions of PostGreSQL appears to be the same features as Service Packs (SP) or Cumulative Updates (CU) for SQL Server. But the main difference is PostgreSQL needs systematically a restart of the database engine when SQL Server does rarely need it! Off course you can use the dreadful pg_prewarm,
Remember that every time you stop the service of a database, every table, index or prepared query execution, is dropped out of the cache, and these new users will have to wait for the queries to compute a new execution plan and charge the cache with the table or index data.
27 – Synonyms?
Although I’m not a fan of synonyms this kind of object can have its use especially for all those who come from the world of Oracle…
There is no synonym in the PostGreSQL world…
SQL Server has add synonyms especially for those coming from Oracle !
28 – Physical data integrity
PostGreSQL provides no way to verify the physical integrity of the data stored, as a regular maintenance task that is done in SQL Server via DBCC CHECK… or with Oracle dbverify (or ALTER TABLE validate) …
This lack of data security can cause severe damages because it cannot be recovered (even the backups can be corrupted). There have been many discussions, since a lot, on this topic:
PostgreSQL Database Data File Integrity Check
Database consistency checker in postgresql
DBCC CHECKDB equivalent in postgres
But the time taken by this process is immeasurably ultra long and therefore totally incompatible with a professional use of databases, especially since it is totally blocking (the SQL Server verification process does not block …).
29- Password security
PostGreSQL does not provide any limit on password login attempts and by default, users can create up to the max_connections config parameter
30 – Maintenance processes
All the maintenance processes in PostGreSQL are terribly time consuming. Especially recomputing optimizer statistics…
- creating indexes over a 10 million rows table are 15 time longer in PostGreSQL…
- rebuilding tables and/or indexes in a 10 million rows, is about 35 to 42 time longer in PostGreSQL!
The lack of indexing diagnostics, to quickly optimize the performance of a database, makes this maintenance task very time consuming. It is in fact necessary to set up a tool for capturing requests, then analyze them one by one, deduce the indexes to be applied, and finally test the gain obtained …
This is a very long approach taking many days in a year for a single PostGreSQL database compares to the way you can do it in SQL Server, taking rarely more than one day to create many hundred indexes over all the databases inside the instance!
Off course PostGreSQL VACUUMing, even in the recent parallel mode, is very very time consuming and totally unexploitable in professional cases!
31 – complexity of system catalog
PostGreSQL has 129 system tables/views in the pg_catalog schema.
|
1 2 3 4 5 6 7 |
SELECT tablename, schemaname FROM pg_tables AS c WHERE schemaname IN ('pg_catalog', 'INFORMATION_SCHEMA') UNION ALL SELECT viewname, schemaname FROM pg_views AS c WHERE schemaname IN ('pg_catalog', 'INFORMATION_SCHEMA'); |
SQL Server 693 (tables, views, DMV, including server level).
|
1 2 3 4 5 6 7 |
SELECT name, type_desc FROM sys.objects WHERE is_ms_shipped = 1 AND type IN ('S', 'IF', 'TF', 'V') UNION SELECT name, type_desc FROM sys.all_objects WHERE is_ms_shipped = 1 AND type IN ('S', 'IF', 'TF', 'V') ; |
Of course there is a big difference in terms of facilitate access to system data and metadata.
As an example, I never find anyway to have a simple query giving the complete list of all relational indexes, with table schema, table name, index name, key columns, ordinal position and order (ASC/DESC). What it is simple to do in SQL Server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT S.name AS TABLE_SCHEMA, T.name AS TABLE_NAME, X.name AS INDEX_NAME, C.name AS COLUMN_NAME, IC.key_ordinal AS POSITION, IC.is_descending_key FROM sys.indexes AS X JOIN sys.tables AS T ON X.object_id = T.object_id JOIN sys.schemas AS S ON T.schema_id = S.schema_id JOIN sys.index_columns AS IC ON X.object_id = IC.object_id AND X.index_id = IC.index_id JOIN sys.columns AS C ON IC.object_id = C.object_id AND IC.column_id = C.column_id WHERE IC.is_included_column = 0 AND X.type BETWEEN 1 AND 2 |
… is a little bit complicated to have in PostGreSQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
SELECT tnsp.nspname as table_schema, tbl.relname as table_name, ic.relname as index_name, CASE WHEN idx.indexprs is null THEN col.attname ELSE pg_catalog.pg_get_indexdef(ic.oid, col.attnum, false) END as column_expression, col.attnum as position, am.amname as index_type, CASE am.amname WHEN 'btree' TNEN CASE idx.indoption[col.attnum - 1] & 1 WHEN 1 THEN 'DESC' ELSE 'ASC' END ELSE null END as column_order FROM pg_index idx JOIN pg_attribute col ON col.attrelid = idx.indexrelid JOIN pg_class tbl ON tbl.oid = idx.indrelid JOIN pg_class ic ON ic.oid = idx.indexrelid JOIN pg_am am ON ic.relam = am.oid JOIN pg_namespace tnsp ON tnsp.oid = tbl.relnamespace WHERE tnsp.nspname NOT IN ('pg_catalog', 'pg_toast') ORDER BY table_schema, table_schema, index_name, col.attnum; |
You have to know 6 tables, write 5 joins, use a function (pg_get_indexdef) deal with a array (indoption[col.attnum - 1]), use three CASEs with two nested CASEs… Will it be simple for an ordinary developer?
Worse is the query which analyzes the rate of fragmentation of tables and indexe. Here is the PostGreSQL version:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
SELECT current_database(), schemaname, tablename, /*reltuples::bigint, relpages::bigint, otta,*/ ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::float / otta END)::numeric, 1) AS tbloat, CASE WHEN relpages < otta THEN 0 ELSE bs * (sml.relpages - otta)::BIGINT END AS wastedbytes, iname, /*ituples::bigint, ipages::bigint, iotta,*/ ROUND((CASE WHEN iotta = 0 OR ipages = 0 THEN 0.0 ELSE ipages::float / iotta END)::numeric, 1) AS ibloat, CASE WHEN ipages < iotta THEN 0 ELSE bs * (ipages - iotta) END AS wastedibytes FROM (SELECT schemaname, tablename, cc.reltuples, cc.relpages, bs, CEIL((cc.reltuples * ((datahdr + ma - (CASE WHEN datahdr % ma = 0 THEN ma ELSE datahdr % ma END)) + nullhdr2 + 4)) / (bs-20::float)) AS otta, COALESCE(c2.relname,'?') AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages, COALESCE(CEIL((c2.reltuples * (datahdr - 12)) / (bs - 20::float)), 0) AS iotta -- very rough approximation, assumes all cols FROM (SELECT ma, bs, schemaname, tablename, (datawidth + (hdr + ma - (CASE WHEN hdr%ma = 0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr, (maxfracsum * (nullhdr + ma - (CASE WHEN nullhdr%ma = 0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2 FROM (SELECT schemaname, tablename, hdr, ma, bs, SUM((1 - null_frac) * avg_width) AS datawidth, MAX(null_frac) AS maxfracsum, hdr + (SELECT 1 + count(*) / 8 FROM pg_stats s2 WHERE null_frac <> 0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename) AS nullhdr FROM pg_stats s, (SELECT (SELECT current_setting( 'block_size')::numeric) AS bs, CASE WHEN substring(v, 12, 3) IN ('8.0', '8.1', '8.2') THEN 27 ELSE 23 END AS hdr, CASE WHEN v ~ 'mingw32' THEN 8 ELSE 4 END AS ma FROM (SELECT version() AS v) AS foo ) AS constants GROUP BY 1, 2, 3, 4, 5 ) AS foo ) AS rs JOIN pg_class cc ON cc.relname = rs.tablename JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema' LEFT JOIN pg_index i ON indrelid = cc.oid LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid ) AS sml ORDER BY wastedbytes DESC; |
This query find in the official PostGreSQL website (https://wiki.postgresql.org/wiki/Show_database_bloat) use 7 subqueries, 9 CASEs, 9 typecast and has near 100 code lines… Let us see the equivalent for Microsoft SQL Server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT s.name AS TABLE_SCHEMA, o.name AS TABLE_NAME, i.name AS INDEX_NAME, avg_fragmentation_in_percent, CASE WHEN i.name IS NULL THEN 'TABLE' ELSE 'INDEX' END AS FRAGMENTATION_LEVEL, (8192 * page_count * avg_fragmentation_in_percent) / 100.0 AS WatedBytes FROM sys.dm_db_index_physical_stats( DB_ID(), NULL, NULL, NULL, NULL) AS ips JOIN sys.objects AS o ON ips.object_id = o.object_id JOIN sys.schemas AS s ON o.schema_id = s.schema_id JOIN sys.indexes AS i ON ips.object_id = i.object_id AND ips.index_id = i.index_id ORDER BY avg_fragmentation_in_percent DESC; |
No subquery, 1 CASE, no typecast, 19 lines…
Accessing metadata and system objects is a nightmare in PostGreSQL. Nothing is simple and system tables changes every version… So, the system queries written for one version will probably have to be rewritten for the next version. What a waste of time!
32 – bug fix
Every time I speak with supporters of open sources about bug fix, they affirm that detecting anomalies is quicker rather than in vendor softwares, and they corrects it more quickly.
But this is quite false. Microsoft is well known to act very quickly when detecting a trouble, much more quiclky than his commercial rival that is Oracle. And what about PostGreSQL, it’s downright much worse…
Let’s talk about a major bug about PostGreSQL’s Linux solution about physical write in files… The bug remains since almost 20 years in PostGreSQL, corrupting data inside tables and indexes… Despite the many users, no one noticed the data corruption? Either very few people use PostGreSQL or they are non-professional users who do not care about the quality of their data …
When Microsoft ported SQL Server to Linux, they made the same error about using Linux’s fsynch code primitives … But between the release of SQL Server (january the 3rd of 2018) and the correction of this bug (CU6, April 19, 2018) it was only 3 and a half months…
So which is the quickest in bugfix? PostGreSQL that takes 240 months or SQL Server that spend only 3.5 months to find and modify the fsynch bug in the Linux version?
33 – Bad advices
A lot of bad advice are being distilled by PostGresSQL aficionados. One of the most frightening consists in saying that it is necessary to always take the type « text » for any literal column instead of CHAR/VARCHAR. It is imbecility that can cost a lot… Indeed, the type « text » has no size limit. It is practical and it could be harmless … Just think about this simple example: by coding a telephone as « text » and associating it with check constraint with a regular expression, if the user decides to enter a made-up telephone number of 1 G bytes of data… The process to verify such an entry can hurt the system and this can be a typical DOS attack!
34 – Stupid terminology
In the RDBMS field, there is a standard terminology to designate such or such element.
In particular, an engine installed from a DBMS is called INSTANCE, but not in PostGreSQL in which we lose a cluster! This term being inappropriate because a cluster is a site regrouping several machines cooperating, converging towards a single solution, which is not at all the case for this unfortunate term chosen by PostGreSQL!
Another inappropriate term is the word planer to refer to the OPTIMIZER. To make the French public laugh, whose term « planer » designates a hover, I amuse myself to say that it is because the staff of PostGreSQL is probably under the influence of LSD! Every other RDBMS uses the term OPTIMIZER …
Perhaps it is by snobbery that PostGreSQL prefers the term relation rather than the term TABLE, to designate a table! However, a relation in the mathematical sense of the term, as defined by Tedd Codd, the creator of RDBMS, has particular properties: key (primary) mandatory, no NULL, atomic data… This is obviously not the case with all tables, and the fact that PostGreSQL allows such exotic types as arrays or enums violates the very principles of relational databases …
By snobbery also PostGreSQL uses wrongly and through, the word tuple to designate a ROW in a table ! The same for attribute, which is simply a COLUMN in a table or a view…
Another stupid term used and abused in PostGreSQL is the word « CLASS« … You will find it at all « sauces » like pg_class, pg_opclass, classoid, indclass, classid…
Are you sure they did know that a RDBMS is not an OODBMS ?
Has Chris Date said – one of the major RDBMS contributor – inapropriate terminology introduce confusion in minds…
You probably noticed right away, […] that I used the formal terms relation, tuple, and attribute. SQL doesn’t use these terms, however – its uses the more « user friendly » terms tables, row, and column instead. And I’m generally sympathetic to the idea of using more user friendly terms, if they can help make the ideas more palatable; instead, they distort them, and in fact do the cause of genuine understanding a grave disservice. The truth is, a relation is not a table, a tuple is not a row, and an attribute is not a column…
SQL and the Relational Theory – How to Write Accurate SQL Code – C. J. Date – O’Reilly 2009
35 – Really OLTP very large databases with PostGreSQL?
There is no ability to perform with huge databases (VLDB OLTP) with PostgreSQL… and I will demonstrate that!
First I have never seen in my life any customer having a PostGreSQL comunity edition working with Tera bytes. The largest databases I have seen is about 300 Gb which for me is near limit of what PG can do without big troubles…
The PG survey: which is declarative, without any control of the given informations, shows that 90% of the databases are under 500 Gb.
This survey do not shows if those metrics are about OLTP or DW databases and does not give the max number of clients accessing the database which is another important figure.
Some paper pointed out really very big databases with PostGreSQL… Really???
« Updating a 50 terabyte PostgreSQL database » FAKE NEWS!
Reading the paper I see :
« We currently process 5,000+ PostgreSQL transactions per second across multiple clusters. »
So, not one database, but perhaps hundreds…
« The largest database in the world – at Yahoo! And it works on PostgreSQL! » FAKE NEWS TO !
This study is more interesting because it is indeed an admission of inability of PostGreSQL performances :
« The Postgres code has been modified to work with such huge amounts of information… »
The CNAF (Caisse National d’Allocations Familiales) is a french social institution. They migrate from a Bull system to PostGreSQL in 2010. The PostGreSQL Magazine talk about a storage of 4 To! Gigantic is’nt it? But on 168 databases…. Which means that databases have an average of size of 24 Gb… ! Source: PostGreSQL Magazine #00 May 2011.
Recently they returned to Oracle…
The historic French national telecommunications operator Orange, had design its own search engine with a PostGreSQL solution…
In this french paper « PostgreSQL usecase : Le Moteur d’Orange« :
They speak about 24 Tb…. but on 800 « postmaster » over 160 servers… I don’t know what « postmaster » is? But if there is 160 servers that means that the average size of the db is 150 Gb. If the « postmaster » is a PG cluster, that means the average size of the db is 30 Gb…
But now, this search engine has been replaced by a call to the Google one, probably because it worked too well!
The French sale adverts website « le bon coin » claims to have a 8 Tb database.
But this testimony given for the « PGdays » in 2014 , says that there is more than 100 servers running PostGreSQL for the 8 Tb of data… Which means that the database size is on average about 80 Gb !
And the website « le bon coin » is currently very criticized with a severe rating (1.5 / 5 on TrustPilot) for its supposedly secure payment technical problems, its faulty delivery providers, the massive presence of scammers …
Is it for a PostGreSQL database crash that « Le bon coin » had a major failure at the end of 2020 and had to compensate many users?
Did the TCO of PostGreSQL is so heavy that they cannot have the money to code some algorithms to detect the presence of criminals ? Or is it because of poor performances of queries that they cannot do so?
Bad news from SQL Server
Of course, as Osgood Fielding III says in the final scene of Billy Wilder 1959 movie: « Nobody’s perfect« … well, SQL Server too!
One terrible thing I hate from SQL Server is that the UNIQUE constraint accepts only one NULL, suggesting that the NULL is unique…
There is a workaround that consists to create a unique filtered index for the non-NULL values…. But it’s a pity. Not Microsoft fault, but Sybase’s one. Like what inheritances are not always good to take.
Good news from PostGreSQL
One thing I like in PostGreSQL is the « Exclusion Constraint », avoiding the use of trigger. I would like this feature be implemented in SQL Server…
Another thing that I do not understand why we don’t have in SQL Server, is the ability to use the standard ISO SQL WINDOW clause!
Congratulation
Finally, I would like to thank Mr. Billel Abidi from Altavia who gave me, despite himself, the idea of writing this paper …