
Un étrange bug (?) nous est apparu dans le cadre d’une nouvelle installation de SQL Server sur une machine physique.
Voici un résumé du problème.
Nous avons installé SQL Server 2019 Enterprise US (15.0.2000.5 / X64 on Windows Server 2019 US Standard 10.0 / Build 17763) sur deux machines physiques toutes neuves et identiques.
Les machines sont les suivantes :
LENOVO – ThinkSystem SR630 – [7X02CTO1WW], avec :
– 1 CPU : 1 Xeon Gold 6208U – 2.90 Ghz (16 cores x 2 – hyperthreading)
– 256 Go RAM (32 Go x 8)
les machines physiques sont strictement identiques et le problème apparait sur les 2 machines…
Le test qui génère les dysfonctionnement sont les suivants :
1) création de la base de données
2) augmentation de la taille des fichiers de la base et mise en mode de récupération SIMPLE
3) création d’une table et d’une vue
4) population de la table avec 1 million de ligne
5) exécution d’une requête de test (calcul d’agrégation d’intervalles de temps)
C’est cette dernière requête (exécutées au moins 10 fois de suite) qui, très souvent, part en erreur, avec le message suivant :
Msg 601, Level 12, State 1, Line … Could not continue scan with NOLOCK due to data movement.
Bien entendu et à aucun moment, nous avons utilisé le tag de requête NOLOCK ni le niveau d’isolation READ UNCOMMITTED.
Mais, lorsque cette erreur survient, des informations complémentaires sont écrites dans le journal des événements de SQL :
1) un time-out de « buffer latch » apparait sur les pages de tempdb;
2) parfois un mini dump est généré;
Exemple de messages « buffer latch » :
A time-out occurred while waiting for buffer latch — type 4, bp 00000292CE3D60C0, page 9:18634, stat 0x10b, database id: 2, allocation unit Id: 422212527063040/140737550352384, task 0x00000292AB073468 : 9, waittime 300 seconds, flags 0x100000001a, owning task 0x00000292AB06B848. Not continuing to wait.
A time-out occurred while waiting for buffer latch — type 4, bp 00000292CE398340, page 6:10372, stat 0x10b, database id: 2, allocation unit Id: 422212527063040/140737550352384, task 0x00000292AB07B468 : 8, waittime 300 seconds, flags 0x1a, owning task 0x00000292AB073468. Not continuing to wait.
A time-out occurred while waiting for buffer latch — type 4, bp 00000292CE3DC480, page 9:18655, stat 0x10b, database id: 2, allocation unit Id: 422212527063040/140737550352384, task 0x00000292AB703C28 : 12, waittime 300 seconds, flags 0x1a, owning task 0x00000292AB07B468. Not continuing to wait.
Nos investigations:
L’installation successive des CU6 puis CU7 pour SQL Server n’a pas résolu le problème
Nous avons éliminé un problème d’erreur disque car nous avons créé la base sur 3 systèmes de disques physiquement différents, de même que nous avons déplacé la tempdb sur ces trois disques (un DBCC CHECKDB a été effectué dans diverses conditions sans jamais rapporter d’erreur).
Alors que « soft NUMA » était actif pour nos premiers tests, nous avons effectué des tests complémentaires en désactivant SOFT NUMA, mais ceci n’a pas résolu le problème.
L’information portant sur le « buffer latch » indique clairement une problématique au niveau mémoire (RAM). Cependant aucun message d’erreur hardware n’a été vu au niveau de la RAM, ni sur quoi que ce soit au niveau hardware.
L’antivirus Symantec a été désinstallé.
Quelques éléments ont fait décroitre le nombre de fois ou le problème s’est produit :
1) désactivation de SOFT NUMA avec l’hyperthreading toujours actif : les 3 premiers tests sont un succès et les 7 suivants partent en échec.
2) désactivation de l’hyperthreading avec SOFT NUMA désactivé : sur 10 tests 1 seul part en échec.
Quelques éléments qui résolvent le problème :
1) le fixage le parallélisme à 1 (ce qui dans les faits désactive le parallélisme)
2) le recalcul des statistiques (UPDATE STATISTICS T_TIME_INTERVAL_TIV WITH FULLSCAN;)
3) la désactivation de l’hyperthreading avec SOFT NUMA activé (plus de 80 tests avec succès)
Nous allons faire un test final en installant un ESX (VMware) sur l’une des deux machines physiques avec l’hyperthreading et SOFT NUMA, et réinstaller SQL Server.
Conclusions
Nous n’avons pas d’idées supplémentaires et soupçonnons que SQL Server utilise un bout de code incompatible avec une particularité du hardware spécifique installé sur ces machines.
Sur d’autres machines similaires avec des barrettes de 16 Go, et en VM nous n’avons pas reproduit cette anomalie.
Après avoir posté dans StackOverflow, plusieurs utilisateurs ont testé cette requête sans reproduire notre anomalie.
https://stackoverflow.com/questions/63702369/msg-601-could-not-continue-scan-with-nolock-due-to-data-movement-but-nolock
Si vous le pouvez, testez ce script sur vos machines afin d’essayer de reproduire ce problème ce qui nous donnera peut être une meilleure idée pour éradiquer ce bug. Aussi n’hésitez pas à nous indiquer votre configuration hard et soft pour les tests que vous effectuez.
Nous avons déclenché une demande d’assistance chez Microsoft.
Si ce problème n’est pas résolu nous le posterons dans Azure SQL feedback…
Merci par avance
--========== SCRIPT ==========--
-- 1) création de la base
CREATE DATABASE DB_BENCH
GO
DECLARE @SQL NVARCHAR(max) = N'';
SELECT @SQL = @SQL + N'ALTER DATABASE DB_BENCH MODIFY FILE (NAME = ''' + name + N''', SIZE = 10 GB, FILEGROWTH = 64 MB);'
FROM DB_BENCH.sys.database_files;
SET @SQL = @SQL + N'ALTER DATABASE DB_BENCH SET RECOVERY SIMPLE;'
EXEC (@SQL);
GO
USE DB_BENCH
GO
-- 2) création de la table et la vue
CREATE TABLE T_TIME_INTERVAL_TIV
(TIV_ID INT NOT NULL IDENTITY PRIMARY KEY,
TIV_GROUP INT,
TIV_DEBUT DATETIME2(0),
TIV_FIN DATETIME2(0))
GO
CREATE VIEW V
AS
SELECT TIV_GROUP AS id, TIV_DEBUT AS intime, TIV_FIN AS outtime
FROM T_TIME_INTERVAL_TIV
GO
-- 3) insertion des données de test
TRUNCATE TABLE T_TIME_INTERVAL_TIV;
GO
BULK INSERT T_TIME_INTERVAL_TIV
FROM "C:\DATA_SQL\intervals.txt"
WITH (KEEPIDENTITY , FIELDTERMINATOR = '\t',
ROWTERMINATOR = '\n');
GO
-- 4) requête de test
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
WITH T1 As
(SELECT id, intime
FROM V
UNION ALL
SELECT id, outtime FROM V),
T2 As
(SELECT ROW_NUMBER() OVER(PARTITION BY id ORDER BY intime) NN, id, intime
FROM T1 T1_1),
T3 As
(SELECT T2_1.NN - ROW_NUMBER() OVER(PARTITION BY T2_1.id ORDER BY T2_1.intime,T2_2.intime) NN1,
T2_1.id, T2_1.intime intime, T2_2.intime outtime
FROM T2 T2_1
INNER JOIN T2 T2_2
ON T2_1.id=T2_2.id
And T2_1.NN=T2_2.NN-1
WHERE EXISTS (SELECT *
FROM V S
WHERE S.id=T2_1.id
AND (S.intime < T2_2.intime AND S.outtime>T2_1.intime))
OR T2_1.intime = T2_2.intime)
SELECT id, MIN(intime) intime, MAX(outtime) outtime
FROM T3
GROUP BY id, NN1
ORDER BY id, intime, outtime;
--========== END OF SCRIPT ==========--
Tests complémentaires (2020-09-29)
Le 29 septembre 2020 nous avons décidé de diminuer le nombre de fichier de la base tempdb à 1. Avec notre paramétrage du parallélisme à 7 (MAXDOP = 7) sur notre machine 16 cœurs / 32 cœurs virtuels (hyperthreading) le bug se produit systématiquement.
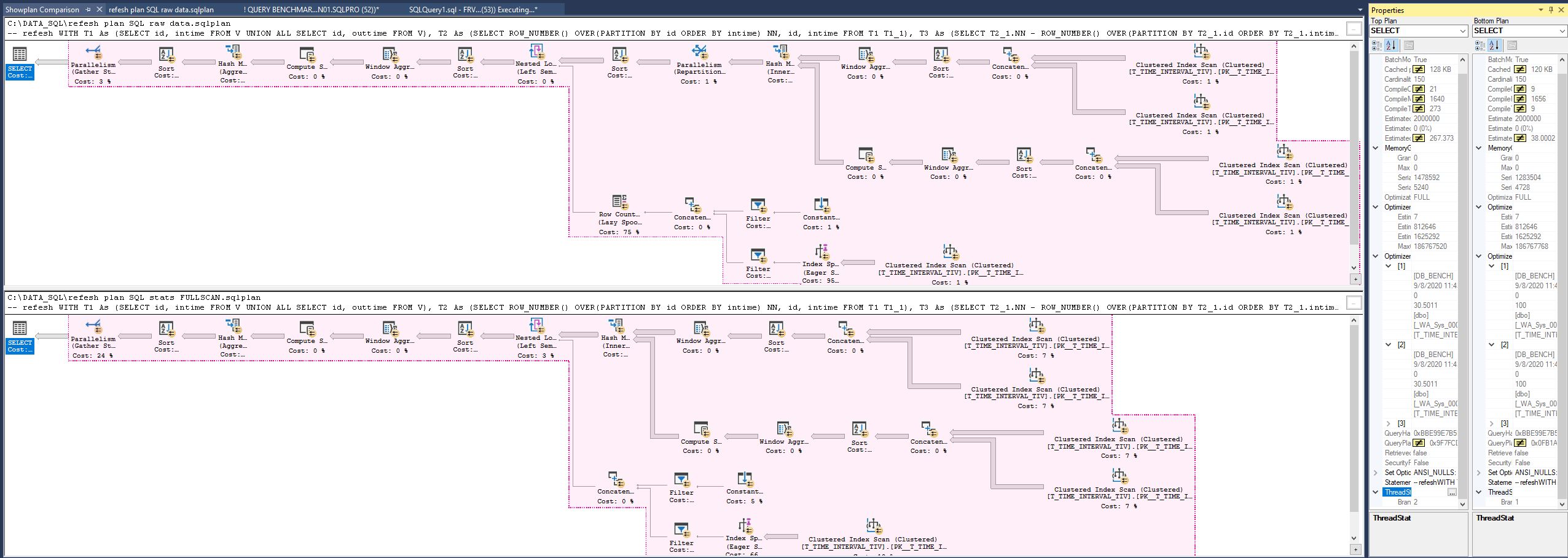
========== PLANS COMPARÉS ==========
Pour information, plans estimé, comparés entre l’exécution brute et après un « UPDATE STATISTICS T_TIME_INTERVAL_TIV WITH FULLSCAN; » :
========== FICHIERS ==========
Fichiers complémentaires :
1) données
https://1drv.ms/t/s!AqvZfiQYoNpBiCD65D4zaRbch5s-?e=UicEYu
2) dump 0005 SQL Server
2.1 – log
https://1drv.ms/u/s!AqvZfiQYoNpBiCPGQ-0QoYbLZY0I?e=sPOwIh
2.2 – mdmp
https://1drv.ms/u/s!AqvZfiQYoNpBiCQzFWYNscBA2wR6?e=vWTdo0
2.3 – txt
https://1drv.ms/t/s!AqvZfiQYoNpBiCEjKy4K5nyv-mfP?e=AbtU4S
2.4 – SQLDUMPER_ERRORLOG.log
https://1drv.ms/u/s!AqvZfiQYoNpBiCIqUVJnczga3kn_?e=DbA8if
3) Plans des requêtes
3.1 – données brutes :
https://1drv.ms/u/s!AqvZfiQYoNpBiCaLh_oQCho2u_WZ?e=tWVrve
3.2 – après un UPDATE STATS en mode FULLSCAN :
https://1drv.ms/u/s!AqvZfiQYoNpBiCUDUQwAwqgwOBAJ?e=Q1fJRO
3.3 – Comparaison des deux plans :
https://1drv.ms/u/s!AqvZfiQYoNpBiCffhVO_PjBNXpOX?e=dZk4Qm

Frédéric Brouard - SQLpro - ARCHITECTE DE DONNÉES - expert SGBDR et langage SQL
* Le site sur les SGBD relationnels et le SQL : https://sqlpro.developpez.com *
* le blog SQL, SQL Server, SGBDR... sur : https://blog.developpez.com/sqlpro/ *
* Expert Microsoft SQL Server, MVP (Most valuable Professional) depuis 14 ans *
* Entreprise SQL SPOT : modélisation, conseil, audit, optimisation, formation *
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
ENGLISH version : http://mssqlserver.fr/nolock-without-nolock-page-latch-time-out-on-tempdb-and-finally-dump/