

La modélisation des bases de données repose sur une théorie mathématique dont le but est de minimiser les IO (Input/Output) ou Entrées/Sortie (E/S) afin de gagner en performance : moins de lecture = plus de performances (chaque IO ou E/S est une opération minimale de lecture sur disque ou en mémoire). Cela évite aussi les anomalies transactionnelles (par exemple que la même personne stockées dans différentes tables ait des caractéristiques différentes…).
La modélisation des bases de données relationnelles repose sur les principes suivants :
-
pas de redondance (un même information en doit figurer qu’à un seul endroit, un même type d’information ne doit pas figurer dans plusieurs tables…)
-
pas de de « NULL » (information vide, mais aussi pas de « mensonge » : information fausse, bidon…)
-
des données atomiques (l’information ne doit pas avoir différentes sémantiques, ce qui arrive si elle est constituée de différents éléments)
-
la modification d’une information ne dois pas impacter plus d’une ligne d’une table.
Hélas on constate souvent le forme de la première forme normale par « apocope »…
Quelques explications sont nécessaires.
Un type de données composé de plusieurs valeurs, comme un tableau, constitue à l’évidence un viol de la première forme normale. Mais ce viol peut être plus subtil s’il est commis en toute discrétion par un ensemble de colonne semblables généralement numérotées afin de satisfaire de possibles informations supplémentaires à discrétion des utilisateurs.
De nombreux éditeurs informatiques utilisent ce principe particulièrement contre performant, avec comme résultat l’impossibilité de retourner rapidement des résultats de requêtes, même lorsque l’on surdimensionne les serveur en RAM, CPU, disques, car toute indexation est vaine généralement dans ce type de modèle.
1 – UN EXEMPLE CONCRET
Voici par exemple ce que j’ai trouvé lors d’un de mes récents audit de bases de données (2023) :

Dans cet extrait d’une table, on note 6 blocs de colonnes ayant des noms similaires à un indice numérique près… Ce sont en fait 6 pseudo tableaux dissimulés dans la structure de la table…
Naïvement la plupart des développeurs croient que ce type de structure ne pose aucun problème, même si ces colonnes sont vide… Hélas il n’est est rien. Faisons le compte :
- un INT coute 4 octets même vide
- un DATETIME coûte 8 octets même vide
- un FLOAT coûte 8 octets même vide
- un VARCHAR, NVARCHAR, VARBINARY… coûte 2 octets même vide
- un BIT coûte réellement un bit même vide, mais à concurrence de 8 bits un seul octet est utilisé
- chaque colonne ajoute un bit supplémentaire dans la matrice de NULLabilité
Au total, toutes ces colonnes, même vide coûtent :
20 x 20 + 2 x 20 + 2 x 10 + 1 + 95/8 = 472 octets…
Partons d’un exemple plus simple donné dans le célèbre site « stackoverflow »…
sql – Best index for table with dynamic predicate – Stack Overflow
(en cas de disparition de cette question cliquez ici pour obtenir l’image de la demande)
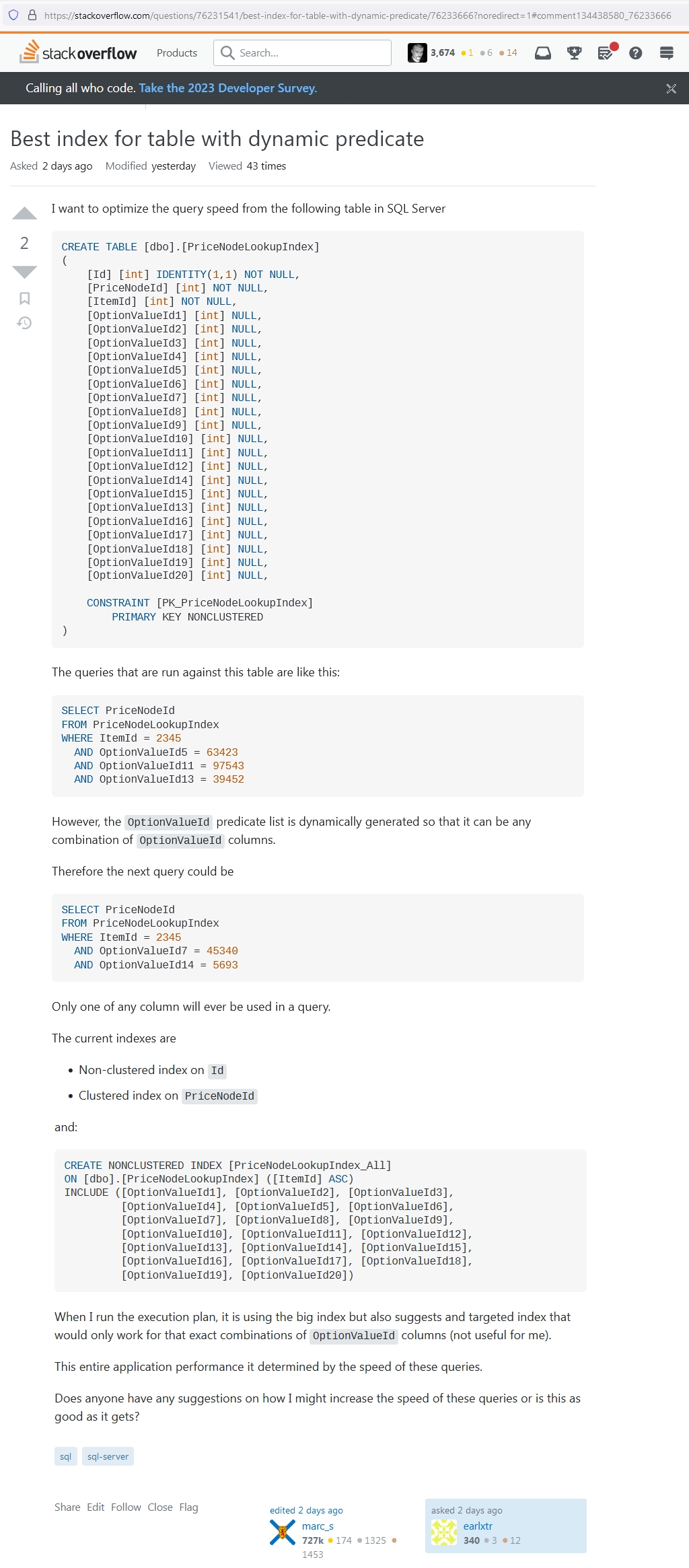{kind=link}
Doté de la table suivante :

Une table violant la première forme normale par apocope (stackoverflow)
Notre quidam tente de rendre performant la requête ci-dessous :
|
1 2 3 4 5 6 |
SELECT PriceNodeId FROM PriceNodeLookupIndex WHERE ItemId = 2345 AND OptionValueId5 = 63423 AND OptionValueId11 = 97543 AND OptionValueId13 = 39452 |
Bien évidemment aucune de ses tentatives de mise en place d’index n’arrive à solutionner le problème global des performances de toutes requêtes dans un tel modèle… Plus exactement, SQL Server lui suggère de créer des index spécifiques pour chaque combinaison des colonnes qui vont figurer dans la clause WHERE…
2 – LE PROBLÈME DE LA PERFORMANCE
Mais notre quidam, nous précise :
This entire application performance it determined by the speed of these queries.
Si nous voulions réellement que toutes les requêtes applicatives possible sur ces colonnes puissent être efficaces, il faudrait un nombre d’index qui est la somme des combinaisons mathématique des colonnes en commençant par des index d’une seule colonne, puis de deux, puis de trois… jusqu’à 20, c’est à dire :
|
1 |
1! + 2! + 3! + 4! +5! +6! + 7! + 8! + 9! + 10! + 11! + 12! + 13! + 14! + 15! + 16! + 17! + 18! + 19! + 20! |
soit :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
1 + 2 + 6 + 24 + 120 + 720 + 5040 + 40320 + 362880 + 3628800 + 39916800 + 479001600 + 6227020800 + 87178291200 + 1307674368000 + 20922789888000 + 355687428096000 + 6402373705728000 + 121645100408832000 + 2432902008176640000 ------------------------ = 2561327494111820313 d'index ! |
En gros plus de 2 milliards de milliards d’index… Heureusement, SQL Server est limité à 1000 index par table. Sinon il y aurait peut être quelque farceur pour tenter une telle aventure… !
3 – LES SOLUTIONS
Les solutions testées l’ont été avec SQL Server 2019 edition Developper dans une table comportant 1 million de lignes sans aucun NULL et sur une machine ayant 128 Gb de RAM et 48 coeurs.
All our solutions have been tested with a 1 million rows table fully filled – no NULL) and MS SQL Server 2019 Developper edition with a machine that runs uder 128 Gb RAM and 48 cores.
3.1 – Par un index vertical
Une première solution qu’il est possible de faire dans certains SGBD Relationnels acceptant les index « verticaux » (columnar) – comme c’est le cas de Microsoft SQL Server avec les index COLUMSTORE – consiste à mettre en place un tel index sur toutes les colonnes de la table. Par exemple ceci se fait simplement en lançant la commande :
|
1 |
CREATE CLUSTERED COLUMNSTORE INDEX XC ON PriceNodeLookupIndex; |
À condition que la table ne soit pas déjà organisée en index clustered…
Cependant c’est une solution que je ne préconise jamais…
- les index verticaux coûtent cher en mise à jour (INSERT, UDPATE, DELETE…)
- l’évolution n’est pas aisée : que se passera t-il si l’on ajoute une 21e colonne ?
- en version Standard dans SQL Server on est limité à 32 Go d’index COLUMNSTORE…
3.2 – La bonne solution par une modélisation correcte
Elle consiste à re-modéliser correctement et faire croire que la table obèse (c’est à dire l’originale) existe toujours…
ÉTAPE 1 – on créé une table annexe pour stocker les n valeurs, comme ceci :
|
1 2 3 4 5 |
CREATE TABLE dbo.PriceNodeLookupIndex_values ( Id INT NOT NULL REFERENCES dbo.PriceNodeLookupIndex ON DELETE CASCADE, Position INT NOT NULL, OptionValue int NOT NULL, CONSTRAINT PK_PriceNodeLookupIndex_values PRIMARY KEY(Id, Position)); |
ÉTAPE 2 – on migre les données de la table originale dans cette nouvelle table :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
INSERT INTO dbo.PriceNodeLookupIndex_values SELECT Id, 1, OptionValue1 FROM dbo.PriceNodeLookupIndex WHERE OptionValue1 IS NOT NULL UNION ALL SELECT Id, 2, OptionValue2 FROM dbo.PriceNodeLookupIndex WHERE OptionValue2 IS NOT NULL UNION ALL SELECT Id, 3, OptionValue3 FROM dbo.PriceNodeLookupIndex WHERE OptionValue3 IS NOT NULL UNION ALL SELECT Id, 4, OptionValue4 FROM dbo.PriceNodeLookupIndex WHERE OptionValue4 IS NOT NULL UNION ALL SELECT Id, 5, OptionValue5 FROM dbo.PriceNodeLookupIndex WHERE OptionValue5 IS NOT NULL UNION ALL SELECT Id, 6, OptionValue6 FROM dbo.PriceNodeLookupIndex WHERE OptionValue6 IS NOT NULL UNION ALL SELECT Id, 7, OptionValue7 FROM dbo.PriceNodeLookupIndex WHERE OptionValue7 IS NOT NULL UNION ALL SELECT Id, 8, OptionValue8 FROM dbo.PriceNodeLookupIndex WHERE OptionValue8 IS NOT NULL UNION ALL SELECT Id, 9, OptionValue9 FROM dbo.PriceNodeLookupIndex WHERE OptionValue9 IS NOT NULL UNION ALL SELECT Id, 10, OptionValue10 FROM dbo.PriceNodeLookupIndex WHERE OptionValue10 IS NOT NULL UNION ALL SELECT Id, 11, OptionValue11 FROM dbo.PriceNodeLookupIndex WHERE OptionValue11 IS NOT NULL UNION ALL SELECT Id, 12, OptionValue12 FROM dbo.PriceNodeLookupIndex WHERE OptionValue12 IS NOT NULL UNION ALL SELECT Id, 13, OptionValue13 FROM dbo.PriceNodeLookupIndex WHERE OptionValue13 IS NOT NULL UNION ALL SELECT Id, 14, OptionValue14 FROM dbo.PriceNodeLookupIndex WHERE OptionValue14 IS NOT NULL UNION ALL SELECT Id, 15, OptionValue15 FROM dbo.PriceNodeLookupIndex WHERE OptionValue15 IS NOT NULL UNION ALL SELECT Id, 16, OptionValue16 FROM dbo.PriceNodeLookupIndex WHERE OptionValue16 IS NOT NULL UNION ALL SELECT Id, 17, OptionValue17 FROM dbo.PriceNodeLookupIndex WHERE OptionValue17 IS NOT NULL UNION ALL SELECT Id, 18, OptionValue18 FROM dbo.PriceNodeLookupIndex WHERE OptionValue18 IS NOT NULL UNION ALL SELECT Id, 19, OptionValue19 FROM dbo.PriceNodeLookupIndex WHERE OptionValue19 IS NOT NULL UNION ALL SELECT Id, 20, OptionValue20 FROM dbo.PriceNodeLookupIndex WHERE OptionValue20 IS NOT NULL; |
ÉTAPE 3 – on supprime les colonnes OptionValueId1 .. OptionValueId20 de la table originale :
|
1 2 3 4 5 |
ALTER TABLE dbo.PriceNodeLookupIndex DROP COLUMN OptionValueId1, OptionValueId2, OptionValueId3, OptionValueId4, OptionValueId5, OptionValueId6, OptionValueId7, OptionValueId8, OptionValueId9, OptionValueId10, OptionValueId11, OptionValueId12, OptionValueId13, OptionValueId14, OptionValueId15, OptionValueId16, OptionValueId17, OptionValueId18, OptionValueId19, OptionValueId20; |
ÉTAPE 4 – on récrit la requête :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT DISTINCT PriceNodeId FROM dbo.PriceNodeLookupIndex AS PN JOIN dbo.PriceNodeLookupIndex_values AS PNV5 ON PN.Id = PNV5.Id JOIN dbo.PriceNodeLookupIndex_values AS PNV11 ON PN.Id = PNV11.Id JOIN dbo.PriceNodeLookupIndex_values AS PNV13 ON PN.Id = PNV13.Id WHERE ItemId = 2345 AND PNV5.OptionValue = 63423 AND PNV5.Position = 5 AND PNV11.OptionValue = 97543 AND PNV11.Position = 11 AND PNV13.OptionValue = 39452 AND PNV13.Position = 13; |
LE BILAN
En terme de performances…
Je me suis amuser à peupler la requête originale de 1 million de lignes avec toutes lkes colonnes valuées (rare en pratique). J’ai ensuite lancé la requête sans aucun index. Les métriques sont les suivantes :
- Cout de la requête originale (sans index) : 11.0137, lectures logiques : 14667.
Avec l’index suggéré par SQL Server :
|
1 2 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[PriceNodeLookupIndex] ([ItemId],[OptionValueId5],[OptionValueId11],[OptionValueId13]); |
Les métriques deviennent :
- Cout de la requête originale (avec un seul index) : 0.00657, lectures logiques : 5
L’amélioration est spectaculaire (1676 fois moindre au niveau coût et 2933 fois moins d’IO) et la requête devient instantannée…
Avec la remodélisation :
- Coût de la nouvelle requête (sans index) : 3.55, lectures logiques 2636
Il est amusant de constater que sans index, le coût de la requête est déjà 3 fois moindre et le nombre d’IO est déjà près de 6 fois moindre…
Avec les index suivants :
|
1 2 |
CREATE INDEX X002 ON dbo.PriceNodeLookupIndex (ItemId); CREATE INDEX X001 ON dbo.PriceNodeLookupIndex_values (OptionValue); |
Les métriques sont désormais :
- Coût de la nouvelle requête (avec index) : 0.02774, lectures logiques 13
L’amélioration est aussi spectaculaire et la requête devient instantanée…
En terme de stockage
La table originale fait 107 Mo de données et 18 Mo d’index (clé primaire)
Avec l’index proposé, il faut rajouter 30 Mo. On peut donc faire l’approximation suivante, chaque colonne dans un index couterait 10 Mo pour cette table d’un million de ligne.
En créant simplement 20 index unitaites sur chacune des 20 colonnes, la volume global serait de 200 Mo. Si nous concevons aussi des index bicolonnes il occuperaient alors 190 (nombre d’index) x 10 Mo, soit 1,9 Go
Avec des index composés de trois colonnes, il faudrait compter plusieurs centaines de Go, mais cela est impossible car nous sommes limités à 1000 index !
La remodélisation n’a besoin que de deux index, l’un sur la table mère, l’autre sur la table fille.
Sans aucun index, ces deux tables ont un volume de 437 Mo (données) et 20 Mo d’index (clés primaires). C’est très proche de la table originale…
Avec les deux index nécessaires et suffisant on passe à : 437 Mo de données data, 397 Mo d’index
En ajoutant une vue de synthèse…
Pour faire croire à notre développeur fou que sa table obèse originale existe toujours nous pouvons faire une vue qui la redessine :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
SELECT Id, PriceNodeId, ItemId, [1] AS OptionValueId1, [2] AS OptionValueId2, [3] AS OptionValueId3, [4] AS OptionValueId4, [5] AS OptionValueId5, [6] AS OptionValueId6, [7] AS OptionValueId7, [8] AS OptionValueId8, [9] AS OptionValueId9, [10] AS OptionValueId10, [11] AS OptionValueId11, [12] AS OptionValueId12, [13] AS OptionValueId13, [14] AS OptionValueId14, [15] AS OptionValueId15, [16] AS OptionValueId16, [17] AS OptionValueId17, [18] AS OptionValueId18, [19] AS OptionValueId19, [20] AS OptionValueId20 FROM (SELECT PN.Id, PN.PriceNodeId, PN.ItemId, V.Position, V.OptionValue FROM questions_76231541.PriceNodeLookupIndex AS PN LEFT OUTER JOIN questions_76231541.PriceNodeLookupIndex_values AS V ON PN.Id = V.Id) AS SRC PIVOT (MAX(OptionValue) FOR Position IN ( [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16], [17], [18], [19], [20]) ) AS PV |
Bien entendu on peut faire croire que cette vues est mise-à-jourable en ajoutant deux déclencheurs INSTEAD OF, l’un sur l’INSERT, l’autre sur l’UPDATE.
Script complet pour tests (MS SQL Server Transact SQL)

Frédéric Brouard - SQLpro - ARCHITECTE DE DONNÉES - expert SGBDR et langage SQL
* Le site sur les SGBD relationnels et le SQL : https://sqlpro.developpez.com *
* le blog SQL, SQL Server, SGBDR... sur : https://blog.developpez.com/sqlpro/ *
* Expert Microsoft SQL Server, MVP (Most valuable Professional) depuis 14 ans *
* Entreprise SQL SPOT : modélisation, conseil, audit, optimisation, formation *