
![]()
Une UDF scalaire (UDF = User Defined Function), c’est à dire une fonction programmée par l’utilisateur et ne renvoyant qu’une seule information, est génératrice de mauvaises performances…
Nous allons démontrer cela…
Malheureusement, les développeurs peu avertis y recourent systématiquement car il préfèrent un code modulaire et itératif (des boucles, encore des boucles, toujours des boucles…) au détriment d’un code ensembliste optimisé !

L’utilisation d’UDF scalaire pose de manière systématique des problèmes de performances… En effet, devant une UDF scalaire, l’optimiseur ne peut :
- Utiliser un index (il effectue une lecture séquentielle)
- Effectuer un traitement de la requête en parallèle
Ce qui pénalise doublement les performances.
De manière générale tout ce qui contrevient aux aspects « ensemblistes » (au sens mathématique du terme) dans une requête, casse le comportement optimal d’exécution et se ressent de façon dramatique sur les performances des requêtes.
Nous allons effectuer des tests pour prouver nos dires et voir comment remédier à la chose…
1 – CRÉATION de la base de tests
USE master; GO -- création de la base de tests CREATE DATABASE DB_TESTS_UDF; GO -- rétrogradation d ela base en version 2008 ALTER DATABASE DB_TESTS_UDF SET COMPATIBILITY_LEVEL = 100; GO --> vous pouvez opter pour la version : -- 2012 (110), -- 2014 (120), -- 2016 (130) -- 2017(140) -- mais pas la version 2019.... ! -- on se place dans le contexte de la base de test USE DB_TESTS_UDF; GO -- création de la fonction (UDF) de conversion de DATETIME2 en DATE CREATE FUNCTION dbo.F_DATETIME2_TO_DATE (@DATETIME DATETIME2) RETURNS DATE AS BEGIN RETURN CAST(@DATETIME AS DATE); END GO -- création d'une table contenant une colonne de type DATETIME2 CREATE TABLE T_DATETIME2 (ID INT IDENTITY PRIMARY KEY, DT DATETIME2); GO
2 – REMPLISSAGE de la table
-- premier remplissage de la table des dates avec 3334 valeurs aléatoires
SET NOCOUNT ON;
DECLARE @I INT = 1, @DT DATETIME2;
WHILE @I < 3334
BEGIN
INSERT INTO T_DATETIME2 VALUES (DATEADD(second, ABS(CHECKSUM(NEWID())), '19500101'));
SET @I += 1;
END;
GO
-- insertion supplémentaire de 11 millions de lignes !
INSERT INTO T_DATETIME2
SELECT DATEADD(millisecond, ABS(CHECKSUM(NEWID())), T1.DT)
FROM T_DATETIME2 AS T1
CROSS JOIN T_DATETIME2 AS T2;
GO
ATTENTION : ça prends du temps (1’22 » chez moi)
3 -TESTS
3.1 – tests n°1
Recherche avec la fonction UDF (F_DATETIME2_TO_DATE), rétro version 2008, aucun index dans la table :
SET STATISTICS TIME ON; GO SELECT * FROM T_DATETIME2 WHERE dbo.F_DATETIME2_TO_DATE(DT) = '2001-09-11'; GO
Aucune importance s’il n’y a aucun résultat…
RÉSULTATS (onglet message) :
Temps d’exécution : Temps UC = 63812 ms, temps écoulé = 73279 ms.
3.2 – tests n°2
Recherche avec le code SQL direct (fonction intégrée CAST) rétro version 2008, aucun index dans la table :
SET STATISTICS TIME ON;
GO
SELECT *
FROM T_DATETIME2
WHERE CAST(DT AS DATE) = ('2001-09-11');
GO
RÉULTAT (onglet message) :
Temps d’exécution : Temps UC = 2296 ms, temps écoulé = 272 ms.
BILAN : sans la fonction UDF, SQL Server est 269 fois plus rapide !
Vous pouvez voir la requête SQL Server en cours d’exécution à l’aide du plan de requête actif. Ceci se fait en cliquant dans SSMS sur l’item « Inclure les statistiques des requêtes actives » dans le menu « Requêtes »
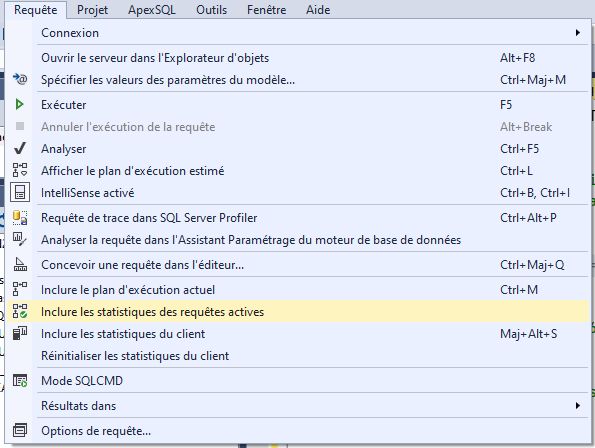
Comment activer les statistiques d’exécution en temps réel du plan de requête SQL Server
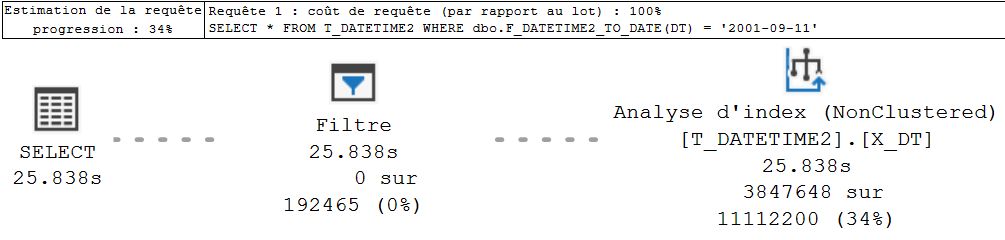
Plan d’exécution de requête SQL Server avec statistiques d’exécution en temps réel
CQFD… mais c’est pas tout ! Voyons voir avec un index…
CRÉATION D’UN INDEX sur la colonne DATETIME2 :
CREATE INDEX X_DT ON T_DATETIME2 (DT); GO
3.3 – tests n°3
Recherche avec la fonction UDF (F_DATETIME2_TO_DATE), rétro version 2008, index X_DT dans la table :
SET STATISTICS TIME ON; GO SELECT * FROM T_DATETIME2 WHERE dbo.F_DATETIME2_TO_DATE(DT) = '2001-09-11'; GO
RÉSULTATS (onglet message) :
Temps d’exécution : Temps UC = 62406 ms, temps écoulé = 71800 ms.
On revient au même temps que le test n°1…
3.4 – tests n°4
Recherche avec le code SQL direct (fonction intégrée CAST), rétro version 2008, index DT dans la table :
SET STATISTICS TIME ON;
GO
SELECT *
FROM T_DATETIME2
WHERE CAST(DT AS DATE) = ('2001-09-11');
GO
RÉSULTAT (onglet message) :
Temps d’exécution : Temps UC = 0 ms, temps écoulé = 0 ms.
BILAN : sans la fonction UDF, SQL Server est infiniment plus rapide !
4 – CORRECTION automatique des UDF
À partir de la version 2019 la mise en place progressive de « l’intelligent query processing » (débuté avec la version 2017) permet de corriger certaines UDF scalaires pour les remplacer par du code direct dans la requête ! Démonstration…
Activons la version 2019 dans notre instance 2019 (ceci n’est évidemment pas possible dans une version antérieure à la 2019 !).
ALTER DATABASE DB_TESTS_UDF SET COMPATIBILITY_LEVEL = 150; GO
4.1 – test n°5
recherche avec la fonction UDF (F_DATETIME2_TO_DATE), version 2019, index X_DT dans la table
SET STATISTICS TIME ON; GO SELECT * FROM T_DATETIME2 WHERE dbo.F_DATETIME2_TO_DATE(DT) = '2001-09-11'; GO
RESULTAT (onglet message) :
Temps UC = 2297 ms, temps écoulé = 247 ms.
BILAN : malgré la fonction UDF, SQL Server a mis exactement le même temps que la fonction intégrée CAST mais n’utilise pas l’index…
Attention, cette transformation n’est pas systématique ! N’en concluez pas qu’il ne faut plus se soucier des UDF… Et notez que l’index n’a pas été utilisé !
NOTA : avez vous remarqué que pour certaines requêtes de test, le temps UC (donc celui passé dans les CPU) était notablement supérieur au temps réellement écoulé ? (Temps UC = 2297 ms, temps écoulé = 247 ms.). Quel est donc ce prodige ?
Ce tour de magie n’en est pas un… Cela est lié au parallélisme. Sur ma machine dotée de 48 coeurs, SQL Server utilise de nombreux threads simultanément pour exécuter les lectures de lignes des tables. Le temps CPU est donc le temps cumulé de chacun des cœurs utilisés. Une simple division nous montre qu’approximativement 9 cœurs ont dû être utilisés (2297 / 247 = 9.3).
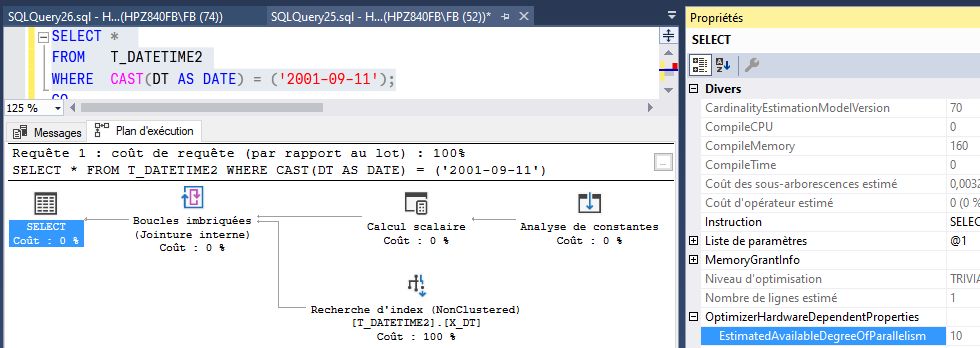
Plan d’exécution et parallélisme SQL Server

Frédéric Brouard - SQLpro - ARCHITECTE DE DONNÉES - expert SGBDR et langage SQL
* Le site sur les SGBD relationnels et le SQL : https://sqlpro.developpez.com *
* le blog SQL, SQL Server, SGBDR... sur : https://blog.developpez.com/sqlpro/ *
* Expert Microsoft SQL Server, MVP (Most valuable Professional) depuis 14 ans *
* Entreprise SQL SPOT : modélisation, conseil, audit, optimisation, formation *
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *